
Personalauswahl ist seit über 100 Jahren ein aktives Forschungsfeld. Doch das Thema bleibt natürlich nicht stehen. Berichte über die Forschungslage sind mithin immer nur Zwischenstände. Wo stehen wir heute?
Sackett, Lievens und Landers haben nun kürzlich eine sehr schöne Zusammenfassung zum aktuellen (Forschungs-)Stand mit dem Titel „Hiring People in Organizations: The State and Future of the Science“ veröffentlicht.

Bei dem einen oder anderen klingelt jetzt vielleicht was… Genau: Paul Sackett und Filip Lievens sind zwei der Autoren einer neuen Meta-Analyse, die sich – grob gesagt – der Frage widmete „Welche Auswahlmethoden eigentlich wie gut zur Vorhersage geeignet sind“. Zu dieser Meta-Analyse gibt es in Fachkreisen einiges an Diskussion und da diese Frage natürlich auch für die Praxis höchstrelevant ist, geistert das Thema auch dort mächtig durch die Welt.
Die Zusammenfassung von Sackett, Lievens und Landers geht nicht nur auf diesen Punkt der Validität klassischer Auswahlmethoden ein, sondern richtet den Blick auch neue Mess- und Diagnostikansätze, beleuchtet Fortschritte bei der Schätzung operativer Validität, diskutiert neue konzeptionelle und technische Perspektiven auf Fairness und Bias, sowie den erweiterten Forschungsstand zu Bewerberreaktionen auf Auswahlverfahren. Abschließend gehen die Autoren auch auf das Thema ein, wie Auswahlsysteme eigentlich durch verschiedene Stakeholder wahrgenommen und akzeptiert werden. Für mich ist Akzeptanz inzwischen so etwas wie ein „kleines Hauptgütekriterium“ geworden, von daher ist es auch nur konsequent, sich dieser auch aus eignungsdiagnostischer Perspektive intensiver zu widmen. Hier wird u.a. auch das Thema „Gamification“ (Game-related Assessment…) besonders beleuchtet, was den „Recrutainment“-Blogger natürlich besonders freut.
Von daher bietet das Review der drei Autoren reichlich Lesestoff und ich werde mich in der nächsten Zeit sicher noch dem einen oder anderen Punkt widmen.
Heute wollen wir aber mit dem ersten Punkt starten:
Der Validität verschiedener Auswahlmethoden…
Ich habe mir daher erlaubt, den Bericht von Sackett, Lievens und Landers noch einmal etwas komprimierter zusammenzufassen und hier und da zu kommentieren und zu erläutern…
STAND DER WISSENSCHAFT: GÜLTIGKEIT TRADITIONELLER AUSWAHLPRÄDIKTOREN
Die Frage, wie gut sich Personalauswahlverfahren tatsächlich „rechnen“, basiert wissenschaftlich auf kriterienbezogenen Validitätsnachweisen – also Studien, die einen Prädiktor (z. B. Test, Interview, Biografie) mit einem Kriterium (z. B. Arbeitsleistung) statistisch in Beziehung setzen. Vllt. habt Ihr in diesem Zusammenhang ja mal den Begriff „Prädiktive Validität“ gehört. Eine einzelne lokale Studie zeigt dabei nur, wie gut ein Verfahren in genau diesem Kontext, diesem Auswahlsetting, dieser Organisation etc. funktioniert. Erst Metaanalysen, die eine große Zahl verfügbare Studien bündeln, liefern das große Bild: den durchschnittlichen Validitätswert und zugleich Hinweise darauf, wie stark Ergebnisse je nach Kontext variieren (jenseits von Zufall/Artefakten).
Seit den 1970er Jahren existieren zahlreiche Metaanalysen zu einzelnen Prädiktor-Kriterium-Beziehungen. Verdichtet wurden diese Befunde in integrativen Übersichten mit „Validitäts-Rankings“ traditioneller Prädiktoren – klassisch bei Hunter & Hunter (1984) und Schmidt & Hunter (1998), aktuell bei Sackett et al. (2022). Ein paar andere habe ich unten auch noch aufgelistet.
Im Zentrum steht dabei meist allgemeine Arbeitsleistung, typischerweise gemessen über Vorgesetztenbeurteilungen. Wichtig ist jedoch: Diese Werte sind nicht automatisch auf andere Kriterien übertragbar, da Prädiktoren je nach Zielgröße sehr unterschiedlich wirken können. So zeigen etwa Studien (z.B. Gonzalez-Mulé et al., 2014), dass GMA (General Mental Ability oder auf Deutsch: allgemeine kognitive Fähigkeit) je nach betrachtetem Kriterium (z.B. Aufgabenleistung oder auch kontraproduktives Arbeitsverhalten) deutlich unterschiedliche prognostische Aussagekraft hat.
Die folgende Übersicht zeigt die ermittelten Validitätsschätzungen verschiedener Auswahlmethoden und stellt diese denen der Meta-Analyse von Schmidt & Hunter aus 1998 gegenüber. Damit auch der statistisch etwas weniger intensiv geimpfte Leser diese Daten versteht, habe ich unter der Tabelle ein paar Erklärungen eingefügt.
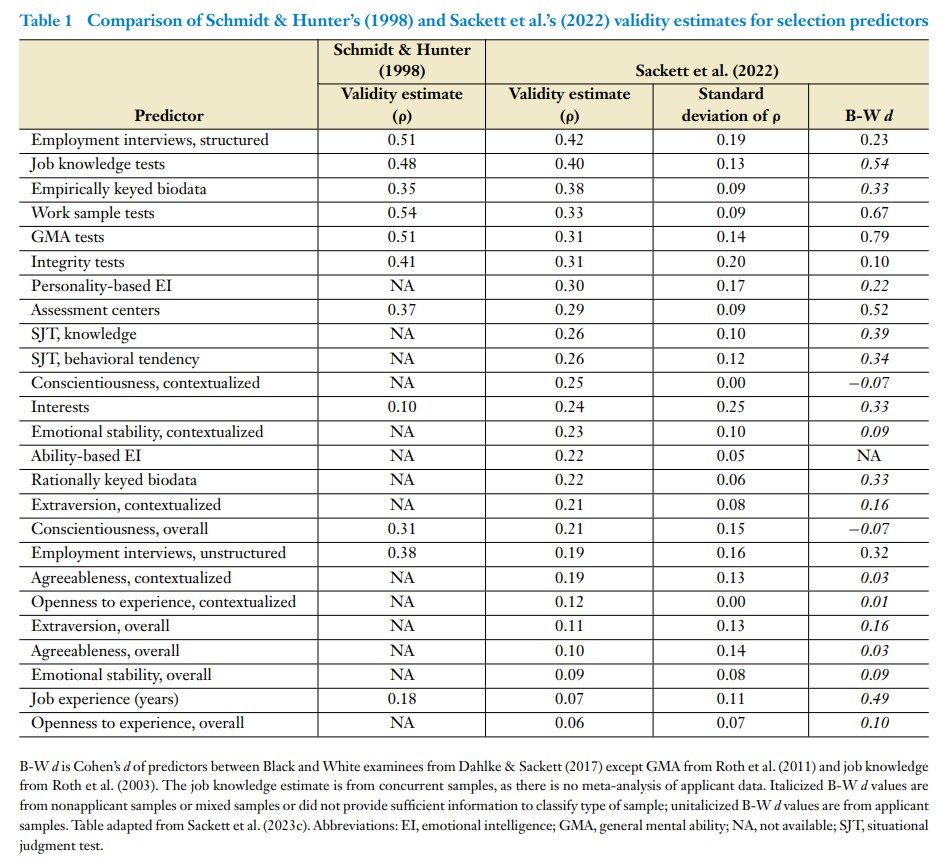
Die Werte in den Spalten „Validity Estimate“ zeigen sog. Korrelationskoeffizienten.
Z.B. berichten Schmidt&Hunter 1998 für strukturierte Interviews einen Korrelationskoeffizienten von 0,54 für Arbeitsproben oder für Assessment Center von 0,37 usw.. Doch was heißt das?
Um diesen Wert interpretieren zu können: Bei einem Korrelationskoeffizient 0,54 werden genau 29,16 % der Unsicherheit (bzw. der Varianz) der abhängigen Variablen bzw. des betrachteten Kriteriums (also z.B. Arbeitsleistung, Ausbildungserfolg etc.) aufgeklärt. Dieser Wert ergibt sich aus dem Bestimmtheitsmaß. Und das Bestimmtheitsmaß errechnet sich aus dem quadrierten Korrelationskoeffizienten (also bei strukturierten Interviews 0,54×0,54 = 0,2916 = 29,16%). Die restlichen 70,84% der Varianz bleiben durch das Modell ungeklärt und werden anderen Faktoren oder dem Zufallsfehler zugeschrieben.
Die Zusammenstellung von Sackett et al. (2022) hat in der Selektionsforschung für ordentlich Unruhe gesorgt. Denn die Autoren berichten nicht nur andere Rangfolgen von Prädiktoren, sondern auch fast durchgehend deutlich niedrigere mittlere Validitäten als Schmidt & Hunter. Beispiele: Arbeitsproben (-0,21) oder unstrukturierte Interviews (-0,19).
Der Hauptgrund hierfür: Frühere Metaanalysen haben lt. Sackett et al. die in Studien unweigerlich auftretenden Messfehler zu wohlwollend korrigiert.
Auch hier schiebe ich für den Praktiker zwei Erklärungen ein:
Bei empirischen Messungen werden gemeinhin zwei Arten von statistischen Korrekturen vorgenommen:
1. Minderungskorrekturen (oder Attenuationskorrekturen) sind statistische Verfahren in der Psychologie und Diagnostik, die Korrelationen zwischen messfehlerbehafteten Variablen korrigieren. Sie schätzen, wie stark zwei Variablen zusammenhängen würden, wenn sie perfekt reliabel (messfehlerfrei) wären. Sie dienen dazu, die „geminderte“ Validität fehlerbehafteter Messungen rechnerisch zu korrigieren.
Einfache Minderungskorrektur: Korrigiert nur die Unreliabilität eines der beiden Messwerte (meist des Kriteriums).
Doppelte Minderungskorrektur: Berücksichtigt die Unreliabilität beider Variablen.
Anwendung: Wenn ein Test oder Kriterium subjektiv oder ungenau ist, hilft die Formel dabei, den wahren Zusammenhang der Konstrukte zu ermitteln.
Die Methode ist essenziell, um die tatsächliche Vorhersagekraft (Validität) von Tests zu beurteilen, da ungenaue Messungen (geringe Reliabilität) Korrelationen künstlich verringern. Jeder, der in der Praxis mal mit (dem Kriterium) Vorgesetztenbeurteilung zu tun hatte, kann erahnen, was hier mit „ungenaue“ Messung gemeint ist…
2. Korrekturen der Varianzeinschränkung (Restriction of Range). Dieses Problem rührt daher, dass Daten für eine Stichprobe nur aus einem begrenzten Teilbereich der eigentlich relevanten Gesamtheit zur Verfügung stehen.
Der Kern: Du schaust dir nur einen Ausschnitt an (z.B. nur die Bestnoten), anstatt das gesamte Spektrum zu betrachten.
Der Effekt: Wenn der Messbereich eingeschränkt ist, sinkt die Korrelation zwischen zwei Variablen künstlich. Zusammenhänge wirken in einer Studie schwächer, als sie in der echten Welt eigentlich sind.
Ein klassisches Beispiel: Möchte man den Zusammenhang zwischen Intelligenz und Studienerfolg prüfen, nutzt man oft Daten von Studenten. Da diese aber bereits vorselektiert sind (nur Leute mit hohem IQ/Abi-Schnitt werden zugelassen), ist die Varianz der Intelligenz in dieser Gruppe geringer als in der Gesamtbevölkerung. Das Ergebnis: Die berechnete Korrelation zwischen IQ und Noten fällt geringer aus.
In diesem Kontext eignet sich m.E. folgende Abbildung immer hervorragend, um das Problem aufzuzeigen:
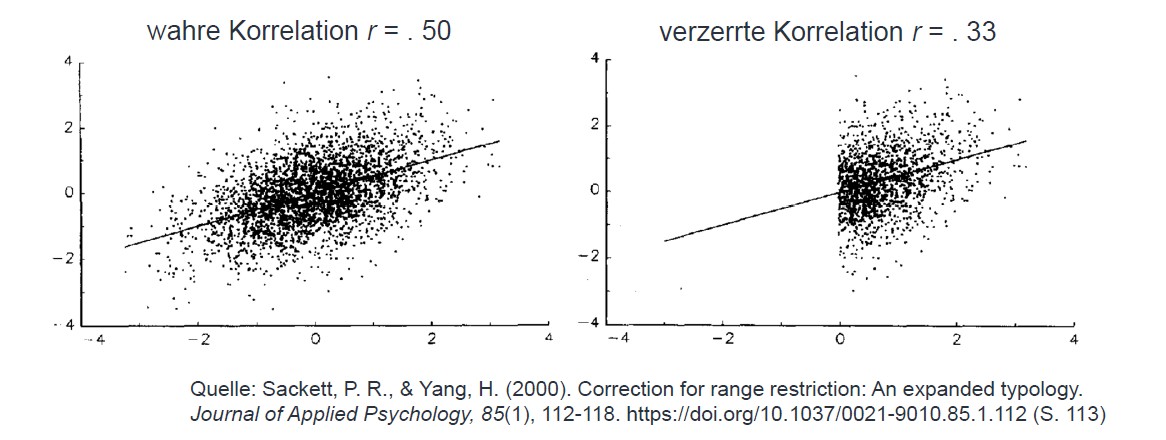
Das linke Bild zeigt den wahren Zusammenhang zwischen dem Kriterium (z.B. das Erfolgsmaß – Berufserfolg o.a. – auf der Y-Achse) und dem Prädiktor (also z.B. dem Abschneiden im Auswahlverfahren auf der X-Achse). Dadurch, dass man ja mit dem Auswahlverfahren auswählt (logisch) bekommt man aber nachher nur für diejenigen, die man eingestellt hat, auch Daten für das Kriterium (nur bei diesen lässt sich z.B. der Berufserfolg beobachten, die anderen hat man ja abgelehnt). Berechnet man nun den Zusammenhang nur auf diesen zur Verfügung stehenden Daten entsteht rein statistisch ein geringerer Wert als der „wahre“ Wert. Hier würde nun die „Korrektur der Varianzeinschränkung“ vorgenommen werden. Tut man dies nicht, kann dazu führen, dass man einen real existierenden Zusammenhang übersieht oder massiv unterschätzt, nur weil die Stichprobe nicht „breit“ genug gestreut ist. Deshalb gibt es in Forschung mathematische Korrekturformeln, um diesen Fehler nachträglich auszugleichen.
Sackett et al. haben nun – verkürzt gesagt – in ihrer Meta-Analyse erheblich weniger korrigiert als es in früheren Meta-Analysen gemacht wurde. So kommen die Autoren bspw. für kognitive Leistungstests auf deutlich niedrigere Korrelationskoeffizienten (durchschnittlich 0,31, also 9,6% Varianzaufklärung gegenüber 0,51, also 26,01% Varianzaufklärung bei Schmidt & Hunter 1998), immer noch eine ganze Menge, aber auch erheblich weniger.
Ihre Begründung: Üblicherweise wird in Metaanalysen ein durchschnittlicher Korrekturfaktor zur Varianzeinschränkung (Range Restriction) aus Studien gebildet, die diese Daten berichten – und dann auf alle Studien angewendet. Das setzt aber voraus, dass diese Studien repräsentativ sind. Genau das ist laut Sackett et al. nicht der Fall. Das Problem liegt im Studiendesign: Rund 80 % der Validitätsstudien sind konkurrent (Test bei bereits Beschäftigten). Dort fehlen in der Regel Daten zum Bewerberpool – und damit die Grundlage für eine saubere Schätzung der Varianzeinschränkung (Range Restriction).
Sackett et al. betonen dabei, dass prädiktive Studien (Test wird wirklich zur Auswahl eingesetzt) typischerweise eine viel stärkere Range Restriction enthalten als konkurrente Studien. Wer nun aber den Korrekturfaktor aus prädiktiven Studien pauschal auch auf parallele oder konkurrente Designs anwendet, korrigiert zu stark – und überschätzt Validitäten teils massiv.
Deshalb fordern Sackett et al. ein konservatives Prinzip: Wenn es keine belastbare Grundlage für Korrekturen gibt, dann lieber unkorrigiert lassen – auch wenn das eine Unterschätzung bedeutet („Validität ist mindestens x“) – statt eine spekulative Korrektur zu nutzen, die zur Übertreibung wird.
Auch an dieser Stelle muss einmal einhaken:
Es gibt aktuell einige Stimmen, die aus dem Sackett et al.-Befunden ableiten, dass z.B. kognitive Leistungstests im Recruiting jahrelang überbewertet wurden, denn die tatsächliche Vorhersagekraft sei ja „nach neuen Erkenntnissen viel niedriger“ als bisher behauptet. Nun, ich denke es dürfte erstens klar geworden sein, dass die niedrigeren Werte vor allem aus sehr viel zurückhaltenderen bis gar nicht vorgenommenen statistischen Korrekturen resultieren. Und zweitens – das betonen und bestätigen die Autoren des Annual Reviews (von denen Sackett und Lievens ja selber zwei sind) explizit – haben Verfahren, die zur Prädiktion / Vorhersage eingesetzt werden, eine erheblich stärkere Varianzeinschränkung. Insofern ist es anzunehmen, dass das pauschale Weglassen oder die sehr viel geringer vorgenommenen Korrektur der Varianzeinschränkung immer dann zu zu niedrigen ausgewiesenen Validitätswerten führt, wenn das Verfahren für die Auswahl eingesetzt wird (was für die meisten hier wahrscheinlich der naheliegendere Einsatzzweck sein dürfte).
Kritiker der Sackett-Meta-Analyse schlagen daher u.a. Metaanalysen vor, die sauber zwischen prädiktiv/parallel/konkurrent unterscheiden und Korrekturen gezielt anwenden.
Wo nun exakt die „wahren“ Werte der Validitäten einzelner Verfahren liegen, kann unmöglich gesagt werden. Es ist hierbei sicherlich erstens nicht ratsam, die Meta-Analysen wie ein „Ranking“ zu lesen im Sinne von „strukturierte Interviews sind das beste Instrument, Fachwissenstest das zweitbeste“ usw., denn die Verfahren übernehmen ja alle ganz andere Rollen in einem Auswahlprozess, kommen an anderen Stellen eines Auswahlprozesses zum Einsatz und sind ja auch nicht singulär zu verstehen: Auswahlprozesse bestehen ja so gut wie immer aus Kombinationen verschiedener Verfahren, auch ein „Assessment Center“ kann ja aus ganz unterschiedlichen einzelnen Verfahren bestehen, Interviews mögen ein tolles Instrument sein, aber man kann in vielen Prozessen unmöglich mit allen Bewerbern ein Interview führen (einen kogn. Leistungstest durchführen hingegen schon) usw.
Zweitens ist ja auch die Verfahrensart (also Interview, Test, Arbeitsprobe etc.) nur ein Teil der Wahrheit – ein schlechtes Interview wird ja nicht dadurch ein gutes Auswahlinstrument, weil man es strukturiert… Insofern ist es auch nicht so entscheidend, dass kognitive Leistungstests von „Platz 2 (Schmidt & Hunter) auf Platz 5 (Sackett et al.) zurückgefallen sind“. Auch Sackett et al. bestätigen ja deren nach wie vor ziemlich gute Prognostik. Zudem waren auch Schmidt & Hunter nicht die einzigen, die in Meta-Analysen eine hohe Vorhersagekraft von GMA herausfanden. Ich nenne hier nur mal exemplarisch folgende Quellen:
- (Speziell für Deutschland) Jochen Kramer: Metaanalytische Studien zu Intelligenz und Berufsleistung in Deutschland
Kramer wertete insg. 244 Studien aus den Jahren 1928 bis 2006 aus und konnte dadurch etwa aufzeigen, dass Intelligenz stark mit Arbeitsleistung (r = .62), beruflicher Lernleistung (r = .59), Einkommen (r = .33) und beruflicher Entwicklung (r = .31) zusammenhängt.
- (Ebenfalls stark auf Deutschland bezogen) Ute Hülsheger, Günter W. Maier und Thorsten Stumpp: Validity of general mental ability for the prediction of job performance and training success in Germany: A meta-analysis
Hülsheger et. al werteten insg. 54 Studien aus, auch und vor allem, um zu überprüfen, ob die in US-amerikanischen oder ganz Europa betreffenden Studien gemessenen Befunde sich auch auf Deutschland übertragen lassen. Sie bestätigten ebenfalls, dass z.B. Lernerfolg (r = .47) und Arbeitsleistung (r = .53) sehr stark mit Intelligenz („General Mental Ability“) zusammenhängen.
- (Mit besonderem Fokus auf UK) Christina Bertua, Neil Anderson, Jesús F. Salgado: The predictive validity of cognitive ability tests: A UK meta‐analysis
Hier wurden insg. 283 Datensamples betrachtet, die den Zusammenhang mit beruflicher Leistung zum Inhalt hatten und 223, bei denen es um Trainingserfolg ging. Die Vorhersage (r) kognitiver Leistungsfähigkeit auf beides lag fast durchweg zwischen .5 und .6, also zwischen 25 und (gut) 30 Prozent.
Dass man nicht den Fehler machen sollte, die lt. der „klassischen“ Meta-Analyse von Schmidt & Hunter von 1998 so stark prädiktiven Auswahlmethoden wie kognitive Leistungstests abzuschreiben wird auch deutlich, wenn man in eine noch aktuellere meta-analytische Betrachtung schaut, die auch u.a. von Sackett und Lievens, also vom in Teilen gleichen Autorenkreis stammt:
In dem Beitrag „Insights from an updated personnel selection meta-analytic matrix: Revisiting general mental ability tests’ role in the validity–diversity trade-off.“ (2024, erschienen im Journal of Applied Psychology) untersuchen Berry, Lievens, Zhang und Sackett die prädiktiven Validitäten von Kombinationen verschiedener Auswahlmethoden.
Und hier zeigt sich insb. eine Kombination aus der Erfassung biografischer Daten und kognitiver Fähigkeiten im Zusammenhang mit der Durchführung strukturierter Interviews als beachtenswerte Verfahrenskombination:

Die hier abzulesenden inkrementellen Validitäten (also diejenigen, die sich ergeben, wenn man Verfahren kombiniert) liegen auf einmal gar nicht mehr so viel unter denen, die Schmidt & Hunter 1998 in ihrer Meta-Analyse herausfanden.
Abschließend: Die bisherige Diskussion fokussiert vor allem Prädiktoren mit ausreichend Forschung für Metaanalysen. Mit wachsender Datenbasis werden feinere Differenzierungen möglich – Sackett et al. (2022) zeigen das bereits, etwa durch die Trennung von kontextbezogenen vs. kontextfreien Persönlichkeitsmaßen oder durch die Unterteilung von SJTs (Situational Judgment Tests) nach Instruktionsformat („should do“ vs. „would do“).
Doch dem Thema widmen wir uns dann in einem späteren Beitrag…
*****
Bisher in der Artikelreihe „Eignungsdiagnostik kompakt“ erschienen:

 . Assessment Center – fundierte Auswahl oder Münzwurf?
. Assessment Center – fundierte Auswahl oder Münzwurf?
 . Was sind eigentlich…? Heute: Biografische Fragebögen: Wie gut ist unsere Vergangenheit als Karriere-Prognose?
. Was sind eigentlich…? Heute: Biografische Fragebögen: Wie gut ist unsere Vergangenheit als Karriere-Prognose?
 . Diskriminierung durch KI in der Personalauswahl. Und durch menschliche Recruiter. Zwei Studien.
. Diskriminierung durch KI in der Personalauswahl. Und durch menschliche Recruiter. Zwei Studien.
 . Anforderungsanalyse: Der Schlüssel für präzise Personalentscheidungen
. Anforderungsanalyse: Der Schlüssel für präzise Personalentscheidungen
. Arbeitszeugnis: Zwischen prognostischem Wert und Wohlwollen. Was die Wissenschaft dazu sagt…
https://blog.recrutainment.de/2025/03/03/eignungsdiagnostik-kompakt-arbeitszeugnis-zwischen-prognostischem-wert-und-wohlwollen-was-die-wissenschaft-dazu-sagt/
 Bias – Warum wir uns täuschen. Und wie wir es besser machen können.
Bias – Warum wir uns täuschen. Und wie wir es besser machen können.
https://blog.recrutainment.de/2025/02/09/eignungsdiagnostik-kompakt-bias-warum-wir-uns-taeuschen-und-wie-wir-es-besser-machen-koennen/
 Was sagen Noten über Intelligenz? Und sind sie ein guter Prädiktor für Berufserfolg?
Was sagen Noten über Intelligenz? Und sind sie ein guter Prädiktor für Berufserfolg?
https://blog.recrutainment.de/2025/02/04/was-sagen-noten-ueber-intelligenz-und-sind-sie-ein-guter-praediktor-fuer-berufserfolg/
 Hobbies und ihre Relevanz in der Bewerbung…
Hobbies und ihre Relevanz in der Bewerbung…
https://blog.recrutainment.de/2024/11/24/eignungsdiagnostik-kompakt-hobbies-und-ihre-relevanz-in-der-bewerbung/
 Was ist eigentlich…? Heute: (berufsbezogene) Persönlichkeitstests im Recruiting: Mehr als nur ein Buzzword?
Was ist eigentlich…? Heute: (berufsbezogene) Persönlichkeitstests im Recruiting: Mehr als nur ein Buzzword?
https://blog.recrutainment.de/2024/10/28/eignungsdiagnostik-kompakt-was-ist-eigentlich-heute-berufsbezogene-persoenlichkeitstests-im-recruiting-mehr-als-nur-ein-buzzword/
 Wie lässt sich die Qualität des Recruitings „beziffern“? Das Brogden-Cronbach-Gleser-Modell…
Wie lässt sich die Qualität des Recruitings „beziffern“? Das Brogden-Cronbach-Gleser-Modell…
https://blog.recrutainment.de/2024/10/18/eignungsdiagnostik-kompakt-wie-laesst-sich-die-qualitaet-des-recruitings-beziffern-das-brogden-cronbach-gleser-modell/
Was ist eigentlich…? Heute: Kognitive Fähigkeitstests
https://blog.recrutainment.de/2024/09/25/eignungsdiagnostik-kompakt-was-ist-eigentlich-eine-heute-kognitive-faehigkeitstests/
Was ist eigentlich ein(e)…? Heute: Die Arbeitsprobe
https://blog.recrutainment.de/2024/08/12/eignungsdiagnostik-kompakt-was-ist-eigentlich-eine-heute-die-arbeitsprobe/
Eignungsdiagnostik kompakt – Heute: Integritätstest
https://blog.recrutainment.de/2024/07/23/eignungsdiagnostik-kompakt-heute-integritaetstest/
Was ist eigentlich ein…? Heute: Das Strukturierte Einstellungsinterview
https://blog.recrutainment.de/2024/07/17/was-ist-eigentlich-ein-heute-das-strukturierte-einstellungsinterview/
Warum wir Intelligenz nicht mit dem Lineal und Persönlichkeit nicht mit dem Thermometer messen können. Erläuterungen zur „klassischen Testtheorie“.
https://blog.recrutainment.de/2024/01/18/warum-wir-intelligenz-nicht-mit-dem-lineal-und-persoenlichkeit-nicht-mit-dem-thermometer-messen-koennen-erlaeuterungen-zur-klassischen-testtheorie/