
Ein neues Jahr… Aber eines ist sicher: KI wird auch dieses Jahr eines der Hauptthemen sein. Doch nach all den sehr vollmundigen Versprechungen und Ankündigungen, mehren sich hierbei die skeptischen oder sagen wir mal zumindest „deutlich weniger euphorisch-aufgeregten“ Stimmen, die auch ein Platzen der KI-Blase nicht für unwahrscheinlich halten.
Bezogen auf den Recruiting-Kontext wird insb. spannend zu beobachten, wie der Collective Action Suit „Mobley vs. Workday“ weitergeht. Dieser könnte all zu autonom agierenden algorithmischen Entscheidungssystemen doch einen erheblichen Dämpfer verpassen.
Ein anderes Thema, das im Zusammenhang mit KI sehr intensiv diskutiert wird, ist die Frage, ob SEO (Search Engine Optimization), also die klassische Suchmaschinenoptimierung, ersetzt wird durch GEO (Generative Engine Optimization), also dem Bestreben, mit den eigenen Inhalten in den Antworten der ChatGPTs, Geminis, Perplexitys und so weiter aufzutauchen.
Ausbildung.de-Chef Felix von Zittwitz hat dies hier vor ein paar Wochen im Interview bezogen auf das Ausbildungsmarketing so beschrieben:
Inhalte müssen so gestaltet sein, dass sie in KI-Dialogen auftauchen. Das wird der neue Wettbewerb.
Ich habe mir hierzu mal ein paar Gedanken gemacht:
GEO statt SEO: Jedem die eigene Wahrheit
SEO war gestern, heute gilt es, mit den eigenen Themen so in den LLMs (ChatGPT, Gemini, Claude usw.) „enthalten“ zu sein, dass diese bei den passenden Anfragen als Antwort ausgespuckt werden. So heißt es zumindest.
Als Menschen googelten, um Antworten auf die sie bewegenden Fragen zu erhalten, war es von entscheidender Bedeutung, mit den eigenen Inhalten in den SERPs („Search Engine Result Pages“) möglichst weit oben aufzutauchen, damit diese Menschen dann auf diesen Content klicken. Das galt für E-Commerce-Betreiber und Shops, um möglichst viel der eigenen Waren zu verkaufen, das galt aber natürlich auch für Arbeitgeber, die ihre Jobs an den Mann oder die Frau bringen wollten. Hier war es dann z.B. das Ziel, die eigene Karriere-Website oder Stellenbörse so auf die relevanten Schlagworte zu optimieren, damit man darunter auch gefunden wird. SEO, also Search Engine Optimization wurde eine eigene Disziplin und es vergeht auch heute immer noch keine Woche, in der einem nicht von irgendeinem Dienstleister versprochen wird, dass er einen „garantiert auf Seite 1“ bei Google bringen kann.
Hast du Hallus, oder was?
Nun, das klingt jetzt alles nach Vergangenheit als gäbe es SEO und Suchmaschinenmarketing nicht mehr. Das ist natürlich Quatsch. Aber seit dem Aufkommen und der massenhaften Verbreitung generativer KI gehen Menschen zunehmend dazu über, sich die Antworten nicht mehr mittels mittels Suche in Suchmaschinen, sondern in Form von Fragen und Dialogen an und mit der KI zu holen. Statt also etwa zu nach „relevante Eignungsdiagnostiker in Deutschland“ zu googlen und dann viele mehr oder weniger relevante Links zur DIN 33430 erhalten, fragt man nun ChatGPT „wer sind relevante Eignungsdiagnostiker in Deutschland“ und erhält eine „sprechende Antwort“.
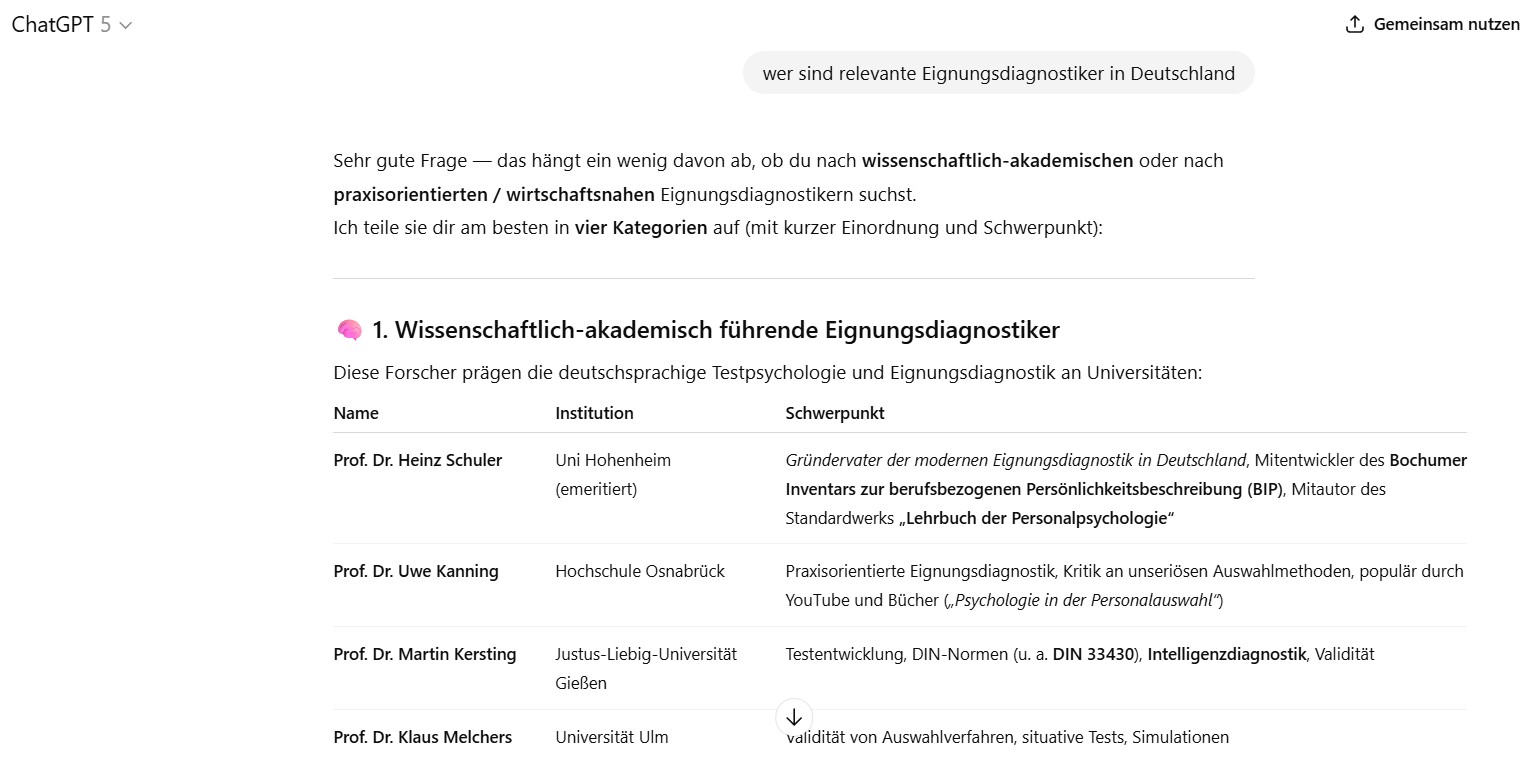

Das sieht erstmal toll aus: Es ist leidlich hübsch aufbereitet – man könnte es direkt per Copy&Paste in eine Präsentation übernehmen. Es ist inhaltlich kein vollkommener Mumpitz – Joachim Diercks gehört natürlich selbstverständlich auf Platz 1 der Liste (😋), wo er ja steht, zumindest bei den Praktikern.
Aber: Da sind schon auf mittelschwere bis heftige Probleme dabei. Die da wären:
Auf der Liste taucht z.B. ein Dr. Jan Wenzel auf. Vielleicht tue ich einem Dr. Jan Wenzel jetzt schwer unrecht, aber ich wüsste nicht, wo er eignungsdiagnostisch wirkt. Bei „CYQUEST“, wie es in der Auflistung steht, jedenfalls nicht. Eine flankierende Google-Suche liefert einen Anhaltspunkt: Es gibt einen Dr. Jan Wenzel, der Pharmakologe und Toxikologe an der Uni Lübeck ist. Dabei hat er sicherlich auch mit „Diagnostik“ zu tun. Nur eben ziemlich sicher nicht mit Eignungsdiagnostik im Sinne der Arbeits- und Organisationspsychologie. Man sieht: ChatGPT hat sich hier erstens „etwas falsches gedacht“ (Diagnostik ist nicht gleich Diagnostik) und zudem etwas falsches hinzugedichtet (Jan Wenzel arbeitet nicht bei CYQUEST).
Jetzt könnte man sagen, „aber Google war ja auch nicht perfekt“. Stimmt natürlich absolut. Aber die Unzulänglichkeit der Suchmaschinenabfrage, führt dazu, dass man weitergehend recherchieren muss. Man folgt Links, man liest auf den aufgerufenen Webseiten, man folgt weiteren Links, betritt und verlässt Sackgassen usw. Mühsam und oftmals unbefriedigend. Aber es führt unweigerlich dazu, dass man sich mit der Materie auseinandersetzen muss. Die Antwort der KI wirkt hingegen fertig, 1:1 verwendbar und so schön aufbereitet, dass sie wohl richtig sein muss. Und das ist genau das Problem, denn es stecken oftmals gravierende Fehler drin. Wir schließen von der Form auf den Inhalt – ein Halo-Bias… Nebenbei geht die Fähigkeit zum Denken und Differenzieren verloren. Früher hieß es „Denken ist wie googlen, nur krasser“, was sagt man wohl in einigen Jahren zur Verwendung von generativer KI…? An dieser Stelle möchte ich gern auf das wie ich finde sehr hilfreiche „PRÜFE-Schema“ (Plausibilität, Recherche, Überzeugungen, Falsifizieren, Entscheiden) von Prof. Barbara Geyer verweisen…
Bohrt man hingegen weiter und bittet die KI um Präzisierung oder weitere Aufbereitung wird es in aller Regel nicht besser, sondern sie verrennt sich im immer tiefer in Fehlern… Ich bin dann z.B. auf Chattys Vorschlag eingegangen, mir eine grafische Übersicht mit dem „Who is Who der Eignungsdiagnostik in Deutschland zu erstellen. Nun seht selbst… Die Top10 sind nur zu acht, eine Person taucht doppelt auf (auch wenn es diese Person nach meiner Recherche in echt gar nicht gibt), die gezeigten Personen sehen in echt anders aus, sofern es sie in der Realität überhaupt gibt, arbeiten meist woanders oder gar nicht in diesem Bereich, die hier genannten Experten weichen von der vorher ausgespuckten Übersicht ab usw.
Kurz: Die KI phantasiert („halluziniert“) fröhlich vor sich hin.

Die Untersuchung „News Integrity in AI Assistants“ der BBC und anderer öffentlicher Medienorganisationen aus 18 Ländern zeigte kürzlich auf, dass fast die Hälfte aller KI-Antworten einen oder mehrere inhaltliche Fehler enthielten.
Das führt uns direkt zu Problem Nummer zwei – die Qualität der Antwort…
Getting MAD: Model Collapse und Model Autophagy Disorder
Vielfach wird bei solchen Einwänden argumentiert: Das wächst sich aus… Die Modelle werden immer besser und derartige Kinderkrankheiten gehören bald der Vergangenheit an.
Das wiederum ist ziemlicher Unfug. Die heute am Markt zugänglichen Modelle haben inzwischen quasi sämtliches verfügbares Menschheitswissen als Trainingsdaten zugeführt bekommen. „Mehr“ Erkenntnis noch irgendwo zu finden, die dann dafür sorgt, dass falsche Antworten auf wundersame Weise richtige werden, ist ausgeschlossen. Vielmehr ist es so, dass durch generative KI neuer Content in die Welt kommt, der dann wiederum selber als Trainingsmaterial in die Modelle wandert – was übrigens der NVIDIA-CEO Jen-Hsun Huang kürzlich in einem Podcast noch einmal deutlich unterstrich (in den nächsten 2-3 Jahren sollen dabei 90% des aufrufbaren Weltwissens bereits selber KI-generiert sein…).
Mal angenommen, die obigen „Antworten“ auf die Frage nach den relevantesten Eignungsdiagnostikern wird von Chatty, Gemini usw. nun wieder verdaut, kann und wird es die diesbzgl. Antwortqualität auf zukünftige vergleichbare Anfragen sicher nicht steigern.
In den KI-Wissenschaften gibt es hierfür auch einen Fachbegriff, der sich ironischerweise mit dem Akronym „MAD“ abkürzen lässt – Model Autophagy Disorder. Dahinter verbirgt sich tatsächlich etwas ähnliches, wie man es auch bspw. von Krankheitsbildern wie Rinderwahn kennt. Wer tiefer in das Phänomen des Model Collapse einsteigen will, dem seien diese drei Artikel ans Herz gelegt:
Model Collapse – die Qualität „lernender“ KI kann sehr wohl auch sinken!
Digitale Krankheit „MAD“ befällt KI-Modelle
Model collapse explained: How synthetic training data breaks AI
Schließlich, Punkt 3:
Jedem seine eigene „Wahrheit“
Eine klassische Suchmaschine gibt keine eigene Antwort, sondern sie sucht und findet die Antworten, die andere gegeben haben. Das „generative“ besteht darin, diese Antworten zu einer Art kuratierten Trefferliste zusammen zu stellen. LLMs wie ChatGPT, aber auch der neue KI-Modus bei Google geben „selber“ Antworten, die sie sich aus all dem, was sie irgendwann mal reingekippt bekommen haben, zusammenreimen.
Speziell beim KI-Modus der Suchmaschinen spricht man in diesem Zusammenhang auch von AI-Overviews bzw. Zero Click Search. Die bei der Antwort ggf. noch angegebenen weiterführenden Links zu den Quellen sind hierbei nicht mehr der Zugang zum Content, sondern degradiert auf die Funktion des „Belegs für die Glaubwürdigkeit des Inhalts“. LLMs sind also nicht Longtail. LLMs sind eigentlich gar kein „Tail“ mehr, denn es gibt nur noch die „eine“ Antwort. Das mag sich praktisch anfühlen, aber ist es auch wirklich im Interesse des Nutzers? Kaum.
Fragen junge Menschen bspw. die KI nach dem zu ihnen passenden Ausbildungsberuf, dann tauchen in dem sehr verengten Antwortkanal nur noch sehr wenige Berufe und tendenziell immer die gleichen auf. Exotischere, aber ggf. viel besser passende Berufsbilder werden systemisch unsichtbar. Auf dieses Problem wird Felix v. Zittwitz bei seinem Spotlight-Vortrag bei der #HREdge26 unter anderem zu sprechen kommen…
Bei AI-Overviews bzw. Zero-Click-Search ist der Suchrahmen, aus dem das LLM die Antwort generiert, eingeschränkt durch die Suchanfrage bzw. die darauf basierenden SERPs. Sinngemäß lautet hier der Prompt „fasse aus den Suchergebnissen zusammen“. Dadurch wird das Wild Guessing erheblich reduziert. Skurrilitäten produziert es dennoch immer noch zu Hauf… Dialoge mit LLMs wie Chatty oder auch AI-Overviews / Zero Click Search funktionieren nur dann und auch nur solange, wie die Person, die die Antwort von der KI bekommt, noch halbwegs in der Lage ist, einzuschätzen, ob die Antwort stimmen kann oder nicht. Ich bin wahrscheinlich halbwegs in der Lage zu beurteilen, ob die obige Einschätzung zu relevanten Eignungsdiagnostikern was taugt oder nicht. Das bin ich aber nur, weil ich mich seit mehr als einem Vierteljahrhundert in dieser Szene bewege. Jemand anderes wäre kaum imstande, das zu beurteilen. Würde ich die KI nach einer rechtlichen Einschätzung zum Mobley vs. Workday-Fall fragen, hätte ich vllt. noch halbwegs ein Gefühl für die Plausibilität der Antwort, aber wirklich sicher wäre ich mir als „Nicht-Jurist“ schon nicht mehr. Bei einer Frage nach der Wirksamkeit des aktuellen Grippeimpfstoffs, wäre ich schließlich komplett blank. Auf die Problematik, dass wir mit zunehmender Verbreitung von „KI-Wahrheiten“ die Fähigkeit verlieren werden, kritisch zu prüfen, haben wir ja vor einiger Zeit schon hingewiesen:
Zudem sind LLM ja auch leider furchtbare People-Pleaser. D.h. sie neigen dazu, Nutzern eine Antwort zu geben, die diesen „passt“ (aber nicht unbedingt „passend“ – iSv. „korrekt“ ist). Das gilt umso mehr, desto länger der User nachfragt oder Zweifel an der Antwort anmeldet. Jeder von euch dürfte die leicht unterwürfige Art der LLM kennen „du hast recht! Meine Antwort stimmte natürlich gar nicht, hier ist eine, die dir besser schmeckt…“. Und je mehr „spezielle Dialoghistorie“ das LLMs mit einem aufbaut (Agents…), desto stärker dürften die individuellen Präferenzen des Users in die Antworten eingebauten werden.

Das galt natürlich auch bis zu einem gewissen Grad auch schon bei Suchmaschinen-Antworten, denn auch die SERPs waren beeinflusst von Endgerät, Ort, Social Graph, Suchhistorie usw., aber im groben und ganzen waren die Suchergebnisse bei gleicher Suche doch für alle die gleichen oder zumindest sehr ähnlich.
KI jedoch liefert jedem seine eigene Wahrheit. Das liegt u.a. daran, dass hier nicht auf Wissen zurückgegriffen wird, sondern die Antwort jedes Mal wieder neu entsteht („generativ“ halt). KI scheitert oft eben schon an der Reliabilität. Sich noch auf irgendeine „allgemeine Wahrheit“ zu einigen (ja, die Erde ist eine Kugel) dürfte so immer schwieriger werden. Das KI die Tür Fake weit aufgemacht hat, ist hinlänglich bekannt (auch wenn wir die Folgen dessen erst beginnen und erahnen, auch im Recruiting…). Zu prophezeien, dass das zudem die Entwicklung von Bubbles und Klangräumen weiter befeuern wird, dürfte auch nicht allzu gewagt sein. Am Ende hat dann jeder seine eigene Bubble.
Auch schön. Da widerspricht wenigstens keiner mehr.
Top Artikel!! Es ist wirklich merkwürdig zu sehen, wie vor allem auf LinkedIn das Thema KI behandelt wird. Ich muss es so hart sagen: Hirnlos! :-) Was in deinem Beitrag aus meiner Sicht fehlt ist der MASSIVE Ressourcenverbrauch. Wenn wir mit KI ausschließlich die Welt retten würden, dann würde das evtl. Sinn ergeben aber für Search und gigantische Mengen an Fun- and Fake-Videos ist das mehr als Grenzwertig. Die Zahlen sind schwer vorstellbar…bis Dato ist kein harter ROI zu sehen schon gar nicht im HR.
zK!
“Die Diskussion um die Fähigkeiten von Künstlicher Intelligenz (KI) erhält durch eine neue Studie von Vishal und Varin Sikka frischen Wind. Die Autoren argumentieren, dass große Sprachmodelle, wie sie derzeit entwickelt werden, mathematisch nicht in der Lage sind, Aufgaben jenseits einer bestimmten Komplexität zuverlässig zu lösen.”