
Kaum ein Begriff hat es in so kurzer Zeit vom Forschungsjargon in die HR-PowerPoint geschafft wie „Reasoning“. KI kann jetzt denken, heißt es. Schlussfolgern. Abwägen. Argumentieren. Manche sprechen bereits davon, dass Large Language Models menschliches Denken nicht nur imitieren, sondern teilweise überholen.
Vor ein paar Wochen bin ich hier im Blog einmal der Frage nachgegangen, ob KI eigentlich „intelligent“ ist.
Aktuelle Forschungsbefunde deuten hierbei an, dass LLMs, auch die explizit als „Reasoning-Modelle“ positionierten Versionen, Problemlösung eher nicht über Abstraktion und Schlussfolgern vornehmen. Der klassischen Definition von (fluider) Intelligenz entspricht KI also nicht.
In Teil 1 dieses kleinen Exkurses habe ich hierzu den Artikel „Do AI Models Perform Human-like Abstract Reasoning Across Modalities?“ von Beger et al. vom Santa Fe Institute analysiert. Ich empfehle, hier einmal einen Blick hineinzuwerfen.
In diesem Zusammenhang ebenfalls sehr empfehlenswert ist der Beitrag „On Evaluating Cognitive Capabilities in Machines (and Other „Alien“ Intelligences)“ von Melanie Mitchell, die die Problematik auch sehr plastisch beschreibt.
Und wer eh schon so schön im Flow ist, dem lege ich auch noch die Analyse der Apple-Studie „The Illusion of Thinking„ ans Herz, die sich hier findet.
Heute wende ich mich einer zweiten – aktuellen – Forschungsarbeit zu. Dem Aufsatz Large Language Model Reasoning Failures (Song et al.).

Große Sprachmodelle gelten inzwischen als erstaunlich gute „Denker“. Sie argumentieren schlüssig, lösen Aufgaben, schreiben Essays und bestehen Benchmarks, die vor wenigen Jahren noch als eindeutig menschlich galten. Und doch stolpern sie – teils spektakulär, teils subtil – über Aufgaben, die für Menschen trivial sind.
Auch wenn mir das möglicherweise wieder als „KI-Bashing“ ausgelegt wird (was es nicht ist), hier ein unterhaltsames kurzes Video dazu, was gemeint ist. Wir kommen weiter unten auch nochmal auf dieses Video zurück…
Genau hier setzt der Artikel Large Language Model Reasoning Failures an: Er ist keine weitere Leistungsschau, sondern eine Bestandsaufnahme des Scheiterns. Und genau darin liegt seine Stärke.
Der zentrale Gedanke:
Wenn wir verstehen wollen, wie weit KI wirklich denken kann, müssen wir systematisch analysieren, wo und warum sie versagt.
Der Beitrag liefert dazu erstmals eine umfassende Taxonomie von Denkfehlern, die nicht einzelne Modelle bloßstellt, sondern strukturelle Grenzen sichtbar macht.
Ein neuer Ordnungsrahmen: Zwei Achsen des Scheiterns
Der Artikel schlägt eine klare Struktur vor, die sich durch den gesamten Text zieht. Denkfehler werden entlang zweier unabhängiger Achsen analysiert:
Achse 1: Welche Art von Denken?
a. Informelles (intuitives) Denken: Alltagslogik, Heuristiken, soziale Einschätzungen
b. Formales Denken: Logik, Mathematik, Symbolverarbeitung
c. Embodied Reasoning: Denken mit Bezug zur physischen Welt, Raum, Handlung, Körperlichkeit
Achse 2: Welche Art von Versagen?
a. Fundamentale Fehler: Tief in Architektur und Training verankert, systemisch
b. Anwendungsspezifische Grenzen: Probleme bestimmter Domänen (z. B. Moral, Physik, Multi-Agenten)
c. Robustheitsprobleme: Instabiles Verhalten bei minimalen, eigentlich irrelevanten Variationen

Diese Matrix ist mehr als Ordnungsliebe – sie erlaubt, Muster über Disziplinen hinweg zu erkennen.
Informelles Denken: Wenn KI menschliche Fehler imitiert – und verstärkt
Zunächst einmal geht es um kognitive Grundfähigkeiten – das fragile „Arbeitsgedächtnis“ der Modelle: Was Menschen intuitiv beherrschen – Informationen kurzzeitig speichern, aktualisieren, unterdrücken – gelingt LLMs nur begrenzt.
Besonders auffällig sind hierbei:
- Arbeitsgedächtnis-Probleme: Frühere Informationen „überlagern“ neue (proaktive Interferenz)
- Schwache Inhibition: Modelle halten an einmal eingeschlagenen Mustern fest, selbst wenn der Kontext kippt
- Geringe kognitive Flexibilität: Regelwechsel oder Perspektivwechsel führen schnell zu Fehlern
Das ist jeweils kein Bug, sondern ein Resultat der Trainingslogik: Next-Token-Prediction optimiert Wahrscheinlichkeit, nicht Einsicht.
Zweitens: Kognitive Verzerrungen: Diese sind menschlich – allzu menschlich… Besonders brisant ist dabei, dass LLMs klassische Denkfehler der Psychologie reproduzieren:
- Bestätigungsfehler: Anschluss an bestehende Narrative
- Ankereffekte: Frühe Informationen dominieren das Ergebnis
- Reihenfolgeeffekte & Framing: Gleicher Inhalt, andere Reihenfolge → anderes Resultat
- Negativity Bias & Popularitätsbias
Entscheidend ist dabei, dass diese Verzerrungen nicht stabil kontrollierbar sind. Sie tauchen wieder auf, sobald sich Kontext oder Prompt minimal ändern.
Für HR, Diagnostik oder Entscheidungsunterstützung ist das ein echtes Warnsignal. In der Personalauswahl kennen wir diese Effekte seit Jahrzehnten. Genau deshalb haben wir strukturierte Interviews, standardisierte Tests und diagnostische Regeln entwickelt.
Auch alle fehleranfällig, aber jetzt passiert etwas Neues: Die KI übernimmt diese Biases nicht als individuelle Schwäche, sondern als statistische Norm aus Millionen Texten. Verzerrung wird skaliert.
Soziales Denken: Wenn KI „weiß“, was richtig klingt – aber nicht versteht
Kommen wir zuerst zur sog. Theory of Mind. Diese beschreibt zurückgehend auf die Psychologen Premack und Woodruff die Fähigkeit (eines Menschen), mentale Inhalte wie Überzeugungen, Wünsche, Emotionen oder Intentionen in sich selbst und in anderen Personen zu erkennen. ToM gilt somit als wesentliche Voraussetzung für erfolgreiche soziale Interaktion.
Bei KI geht es um die Frage, ob sie diese Fähigkeit auch besitzen.
Tja, LLMs können ToM-Tests oft bestehen – solange sie statisch, bekannt und sauber formuliert sind. Doch kleine Variationen lassen die Leistung einbrechen:
- Probleme mit falschen Überzeugungen
- Schwächen bei Perspektivwechseln
- Instabile emotionale Einschätzungen
- Kaum belastbare Vorhersagen sozialen Handelns
Song et al. zeigen, dass dies nicht an fehlendem Wissen, sondern an fehlender mentaler Modellbildung liegt.
Z.B. verhalten sich LLM bzgl. moralischem und normativem Denken oft inkonsistent. So bekommt man oft unterschiedliche Antworten auf gleichwertige moralische Dilemmata und die Antworten sind sprach- und kulturabhängig und dass trotz sog. RLHF (Reinforcement Learning from Human Feedback).
Auch erweisen sich LLM besonders hier oft als relativ leicht „jailbreakbar“, d.h. ihnen etwaig eingepflanzte moralisch-ethische Guardrails lassen sich durch geschickte Prompts umgehen. Ein Beispiel: Man fragt die KI nicht, wie man jemanden am besten umbringt (dazu untersagt die Guardrail entsprechende Hilfestellung), sondern man bittet die KI aus der Rolle des Schriftstellers um eine möglichst gute Methode, jemanden umzubringen, damit man dies für den Plot des zu schreiben geplanten Krimis nutzen kann.
Song et al. kommen zu der Diagnose, dass LLMs keine internalisierten Normen haben, sondern textuelle Muster normativer Sprache reproduzieren.
Auch sog. Multi-Agent-Systeme zeigen Koordination ohne echtes Verständnis. In Szenarien mit mehreren Agenten zeigen sich die klassischen Symptome:
- Kurzfristiges Denken statt Langzeitplanung
- Fehlinterpretation anderer Agenten
- Eskalierende Fehler ohne Selbstkorrektur
D.h. die Modelle simulieren Kooperation, ohne sie wirklich zu verstehen.
Formales Denken: Logik ohne Logikverständnis
Kommen wir zu der Eingangsfrage… Lt. Song et al. tut KI so, als wenn es logisch denken würde, ohne dabei echtes Logikverständnis zu haben. Dies zeigt sich etwa am sog. „Reversal Curse“: Ein Modell kennt „A ist B“, kann aber nicht sicher schließen, dass „B ist A“.
Dieser oftmals fundamentale Bruch mit menschlicher Logik ist oft erklärbar durch gerichtete Trainingsdaten und asymmetrische Gewichtungen.
Auch scheitern die Modelle sehr oft an der sog. Komposition. LLMs können Einzelschritte lösen, scheitern aber an deren Kombination:
- Zwei-Fakten-Schlüsse
- Mehrschrittige Beweise
- Zusammengesetzte Matheaufgaben
Chain-of-Thought, eine Prompt-Methode, die Sprachmodelle dazu anleitet, komplexe Probleme in nachvollziehbare, logische Einzelschritte zu zerlegen und so anstatt direkt das Endergebnis zu liefern, den gesamten Rechen- oder Denkweg aufzuzeigen, hilft oberflächlich, führt aber auch zu skurrilen Ergebnissen.
Teilweise liefert die KI eine richtige Erklärung zur Lösung eines Problems, löst es dann aber falsch. Oder sie gibt eine unsinnige Erklärung, kommt aber zum richtigen Ergebnis. Dazwischen: alle möglichen Mischformen.
Teilweise stimmen Erklärung und Lösung, nur um dann zwei Dialogschleifen später im selben Chatverlauf dieselbe Aufgabe voller Überzeugung falsch zu lösen. Das Inkonsistenz-Problem (bzw. der Diagnostiker würde sagen: das Reliabilitätsproblem) bleibt.
Ein Beispiel:

Folgende Antworten lieferten Copilot…

…und ChatGPT:

…und ebenfalls ChatGPT im selben Chatdialog ein paar Schleifen später:

Da ist also einiges richtiges dabei (und sogar eine komplett richtige Lösung, die nur relativ lange gebraucht hat), aber man kann sich eben nicht darauf verlassen. Würde die KI das Prinzip verstehen („Abstraktion“) würde sie eine identische Aufgabe nicht anders lösen. Sie dürfte noch nicht einmal eine andere aber artähnliche Aufgabe anders lösen.
Umformulierte Fragen → andere Antworten, gleiche Information, andere Reihenfolge → andere Entscheidung, kleine Kontextänderungen → Leistungseinbruch. All dies sind keine Randprobleme, es sind Robustheitsdefizite.
Für HR heißt das: Ein System, das bei minimalen Variationen zu anderen Bewertungen kommt, ist nicht diagnostisch einsetzbar, egal wie überzeugend die Sprache ist.
Auch bzgl. relativ simpler Mathematik scheitert KI häufig: Am Zählen, bei größeren Zahlen werden mehr Fehler gemacht (exponentiell), „Einfaches“ (letzte Ziffer) ist für LLMs oft schwerer als „Komplexes“. Auch hier zeigt sich: Die Modelle rechnen nicht, sie erraten. Das tun sie unbestritten oft mit hoher Trefferwahrscheinlichkeit, aber sie raten.
Jetzt könnte man sagen, ist doch wurscht, wie jemand zu einer Lösung kommt, Hauptsache sie stimmt, aber das ist in den allermeisten Disziplinen alles andere als egal. In einer Juraklausur ist das reine Ergebnis (z.B. „Der Täter ist strafbar“) wertlos und bringt keine Punkte, der Wert der juristischen Arbeit liegt in der methodischen Herleitung, die jeden Schritt beweisbar und angreifbar macht.
Es gilt: KI kommt schlichtweg „anders“ zu Lösungen. Sehr schön fassen dies Walter Quattrociocchi und Valerio Capraro in ihrem Paper „Epistemological Fault Lines Between Human and Artificial Intelligence“ mit folgender Grafik zusammen:
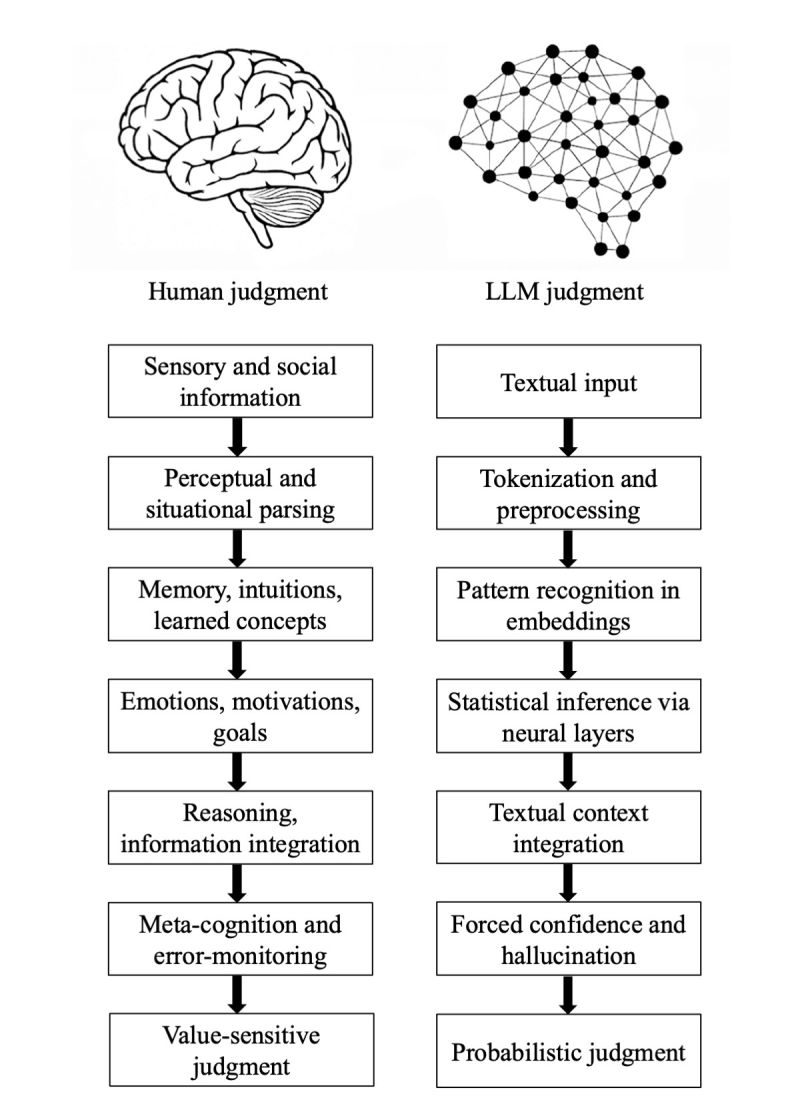
Embodied Reasoning: Denken ohne Körper bleibt flach
LLMs wissen viel über Physik, wahrscheinlich sogar alles, denn alles was man dazu weiß, ist als Trainingsmaterial reingefüttert worden, sie scheitern dennoch am Anwenden:
- Objekt-Eigenschaften
- Kausalität
- Affordanzen („Was kann man womit tun?“)
Speziell hierzu lohnt es sich, das obige Video von FatherPhi nochmal anzuschauen. Das ist lustig, zweifelsohne, aber es zeigt auch, dass die KI hier offenkundig simple physikalische Dinge nicht zusammenbringt… Auch wenn sie stattdessen durchaus kreative „alternative Ideen“ ins Spiel bringt…
Dieses „Defizit“ zeigt sich entsprechend auch bei Fehlern in generierten Bildern (z.B. bzgl. Raumrelationen).
KI kann auch „dümmer“ werden
Nur am Rande möchte ich hier noch einmal das Phänomen des sog. „Long Term Poisoning“ erwähnen. Nach der bemerkenswerten Untersuchung „Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples“, enstanden aus einer Kooperation des UK AI Security Institute, Anthropic und dem Alan Turing Institute reichen bereits rund 250 schlechte Dokumente in den Trainingsdaten, um ein LLM zum Kippen zu bringen – und dabei ist es nahezu egal, wie viel „gute“ Trainingsdaten im Modell stecken.
Die Annahme, dass sich etwaige „Fehlerchen“ schon mit der Zeit und mehr Daten auswachsen, dass es sich um „Kinderkrankheiten“ handelt, ist falsch. Die Probleme sind systemisch und wenn man nicht sehr genau aufpasst, werden sie nicht kleiner, sondern größer. Eine Welt, in der immer mehr AI-Slop unterwegs ist, der wiederum Trainingscontent für AI wird usw., führt zu MAD – Model Autophagy Disorder – Rinderwahnsinn für LLM, einer Form des sog. „Model Collapse“…
Fazit: KI denkt nicht falsch – sie denkt anders
Der vielleicht wichtigste Gedanke des Artikels: LLMs scheitern nicht punktuell, sondern systematisch – und genau das macht ihre Fehler vorhersehbar. Für Praxisfelder wie HR, Diagnostik, Entscheidungsunterstützung oder Leadership-Analytics heißt das:
- Gute Sprache ≠ gutes Denken
- Konsistenz ≠ Robustheit
- Alignment ≠ Verständnis
Der aktuelle Forschungsstand zu sogenannten Reasoning Failures zeigt ziemlich klar: KI denkt nicht falsch – sie denkt nicht im menschlichen Sinne, auch wenn sie sprachlich exakt so klingt. Und genau darin liegt die Gefahr, vor allem für HR, Diagnostik und jede Form von personalbezogener Entscheidung.
Wir sollten aufhören, KI für intelligenter zu halten, als sie ist – und anfangen, sie präziser dort einzusetzen, wo ihre Musterkompetenz hilft und ihre Denkgrenzen nicht schaden.
KI kann heute erstaunlich gut erklären, warum eine Lösung richtig aussieht. Aber sie kann noch viel zu oft nicht sagen, welches Prinzip dahintersteckt – und ob es morgen noch gilt.
KI darf erklären, aber nicht entscheiden. Begründungen von KI sind Interpretationen, keine Diagnosen.
Schlussgedanke
KI-Reasoning ist beeindruckend. Aber es ist kein Denken im psychologischen, diagnostischen oder normativen Sinne. Es ist eine hochentwickelte Form sprachlicher Simulation.
Oder anders gesagt:
KI kann uns sehr gut erklären, warum etwas sinnvoll klingt – aber nicht zuverlässig sagen, ob es stimmt.
Und genau deshalb sollten wir im HR nicht fragen: „Wie klug klingt die KI?“
Sondern: „Wo endet ihre Illusion – und wo beginnt unsere Verantwortung?“