
Es ist doch ein Kreuz mit dem Bloggen… Manchmal wünschte ich mir, ich könnte das hauptberuflich machen, weil es a. soviel und b. vor allem soviel Spannendes zu berichten gibt. Leider muss ich auch immer noch operativ arbeiten, um zwischen dem Bloggen ab und an ein wenig Geld zu verdienen (und auch um die hier erzählten Geschichten zuweilen mal mit der einen oder anderen selbst gemachten Erfahrung würzen zu können ;-) …
Naja, das führt dann eben dazu, dass manchmal doch viel mehr Zeit verstreicht bis man seinem Versprechen nachkommt und z.B. die Fortsetzung einer Artikelserie dann auch liefert… So ging es mir auch mit der Serie über Matching und in diesem Zusammenhang spannende Anbieter und Startups. Teil 1 stammt aus dem Februar und auch Teil 2 liegt inzwischen schon wieder 6 Wochen zurück.
Matching über Big Data
Heute geht es aber endlich weiter und ich fange an, mich den wirklich dicken Brettern zu nähern, nämlich denen, wo das Thema Matching so richtig was mit Big Data, künstlicher Intelligenz und hochkomplexen selbstlernenden Algorithmen zu tun hat.
Bei dem geschätzten Bloggerkollegen Stefan Scheller lief ja vor kurzem ein wirklich viel beachtetes (zu Recht!) HR-Blind Battle zwischen Jan Kirchner und Michael Witt rund um die Frage, ob Maschinen (Roboter) eigentlich die besseren Recruiter seien. Das Ergebnis der Abstimmung war recht eindeutig: Mehr als 72% sagten „der Mensch“.
Tja, ich fand, dass man in diesem konkreten Fall die Reduzierung auf ein „Entweder-Oder“ eigentlich nicht machen kann, weil beides richtig ist. Manches können Maschinen schlichtweg besser, manches Menschen. Das brachte unlängst der Deutsche Lutz Finger, der bei LinkedIn für eines der wahrscheinlich größten Projekte zur automatisierten Vorhersage von Jobmatchings überhaupt verantwortlich ist, wunderbar auf den Punkt: Big Data kann die Zukunft nicht voraussagen, aber Muster erkennen, die die Wahrscheinlichkeit erhöhen, dass Kandidat und Unternehmen zusammenpassen, auch wenn
Bauchgefühl und persönlicher Eindruck weiterhin eine Rolle spielen werden.
Vor allem aber bringt meines Erachtens das Abstimmungsergebnis zum Ausdruck, dass viele Personaler entweder noch romantisch der alten Zeit nachhängen oder schlichtweg zu wenig wissen, was alles inzwischen schon von Algorithmen geleistet werden kann und geleistet wird…
Ich betrachte das als Ansporn, weil ich glaube, dass nur Kenntnis und Aufklärung am Ende dazu führen wird, das beste aus beiden Welten miteinander zu vereinen und eben kein „Entweder-Oder“ daraus zu machen.
Wir haben daher „Matching und Big Data“ zu einem Schwerpunktthema der HR-Edge am 10. September gemacht, wo uns Tim Pröhm von Joberate einiges dazu erzählen wird, wo aber vor allem auch die Möglichkeit angeboten wird, quasi einmal am eigenen Leib zu erleben, was Algorithmen inzwischen über einen selber so wissen… BTW: Man kann sich übrigens inzwischen für die HR-Edge anmelden, wozu ich auch nur dringend raten kann, weil es ein solches Event sowohl inhaltlich als auch von der äußeren Form so nicht noch einmal gibt…

Doch zum Thema. Matching über Big Data…
Stell dir vor, die Maschine weiß vor dir, dass du kündigen willst…
Da wir ihn bei der HR-Edge dann auch da haben werden, habe ich mir Tim mal geschnappt und mir einmal zeigen und erklären lassen, was Joberate eigentlich genau macht und wie hier Algorithmen arbeiten, um am Ende unter anderem auch Matching zu ermöglichen bzw. zu verbessern:
Ganz knapp gesagt:
Joberate errechnet in Echtzeit Kündigungswahrscheinlichkeit.
Klingt ja erst mal ganz einfach. Aber wozu soll das gut sein? Was hat das mit Matching zu tun? Und wie soll das denn bitte gehen?
Ich fange mal mit Frage 3 an. Wie geht das?
Wir alle bewegen uns ständig in irgendeiner Form im Netz und hinterlassen dabei Datenspuren. Veralgorithmierbare und damit auswertbare Datenspuren. Lt. IBM-Schätzung produzieren wir alle zusammen täglich rund 2,5 Quintillionen Bytes an Daten, was grob 50 Quadrillionen vollgeschriebenen DIN A4 Blättern Text (oder 5 Quadrillionen Blogartikeln dieser Länge…) entspricht. Ob wir das mehr oder weniger bewusst und gesteuert tun, z.B. wenn wir gewissen Meinungen über den Twitteraccount kundtun, nach etwas bei Google suchen, etwas bei amazon kaufen oder etwas bei Facebook liken, oder ob das eher verborgen passiert, z.B. indem Facebook „Bewegungsprofile im Netz“ erstellt (auch wenn ich gar nicht bei Facebook angemeldet bin), Apple mein „echtes“ Bewegungsprofil anhand von Standortdaten ermittelt (auch wenn GPS aus ist etwa anhand aktiver WLANs in meinem Umfeld oder mindestens auf Basis der Funkzellen, in denen sich mein Telefon gerade befindet) oder Websites, die ich aufrufe, alle möglichen Informationen aufzeichnen (z.B. mit welchem Gerät, welchem Browser, mit welchen installierten Schriftarten usw.) ist vollkommen egal. ALLE Informationen werden gespeichert und stehen nachfolgend für darauf basierende Analysen zu Verfügung.
Im Falle von Joberate sind das z.B. Informationen, die sich aus den eigenen Aktivitäten in sozialen Netzwerken ergeben: Den zugänglichen Informationen aus beruflichen Netzwerken wie XING oder LinkedIn, den Kontakten, den Inhalten und Aktivitäten bei Twitter und Facebook usw.
Nicht dass wir uns falsch verstehen: Da sitzt natürlich jetzt kein Mensch davor und schaut nach, was ich so bei Twitter den lieben langen Tag absondere. Das wandert alles vollautomatisiert in die Datenbank. Und dabei wird auch nicht mühsam das Sichtbare kopiert und gespeichert, also das was man z.B. bei twitter.com/recrutainment sehen kann. Nein, die Daten kann man direkt kaufen. Und zwar bei sog. Social Data Aggregatoren. Diese Anbieter sind den meisten – selbst denjenigen von uns, die sich täglich mit Fragen des Social Media befassen – in der Regel unbekannt, aber sie sind im Prinzip so etwas die Rohstoff-Konzerne des digitalen Zeitalters: Postano, Tint, Datasift, swoop, Gild, Stackla, Gnip und wie sie alle heißen. Von Hootsuite hat vielleicht schon mal der eine oder andere gehört. Manche haben sich vielleicht schon mal gefragt, warum Hootsuite einem eigentlich kostenlos bzw. kostengünstig Tools zur Verfügung stellt, über die man verschiedene Social Networks zentral überblicken und verwalten kann. Nun, die Antwort ist einfach: Weil dann auch Hootsuite sehr einfach und wunderbar sortiert die verschiedensten Social Media Aktivitäten überblicken kann. Und diese Informationen werden handelbar und sie werden auch gehandelt. Wenn ich also meinen kompletten Twitterstream der letzten knapp sechs Jahre kaufen wollte, dann könnte ich dies bei einem Social Data Aggregator tun. Und wenn ich das nicht nur von mir, sondern von vielen Menschen und nicht nur für Twitterdaten, sondern von vielen Plattformen tue, dann ist das ein Datenschatz, in dem sich viele spannende Informationen verstecken können.
Das Prinzip von Big Data ist es nun, mit immenser Rechnerleistung innerhalb dieses Datenschatzes nach Strukturen zu suchen. Das entscheidende dabei ist, dass bei Big Data erst einmal nicht die Kausalität im Zentrum der Betrachtung steht, sondern die Korrelation! Erst einmal wird geschaut, ob gewisse Merkmale häufig gemeinsam auftreten. Erst dann wird, wenn überhaupt, nach einem möglichen Grund dafür gesucht.
Im Falle von Joberate nun geht es darum, aus dem immensen verfügbaren Fundus an Informationen einen zentralen Wert zu berechnen:
Die Jobwechsel-Wahrscheinlichkeit, ausgedrückt durch den sog. J-Score.
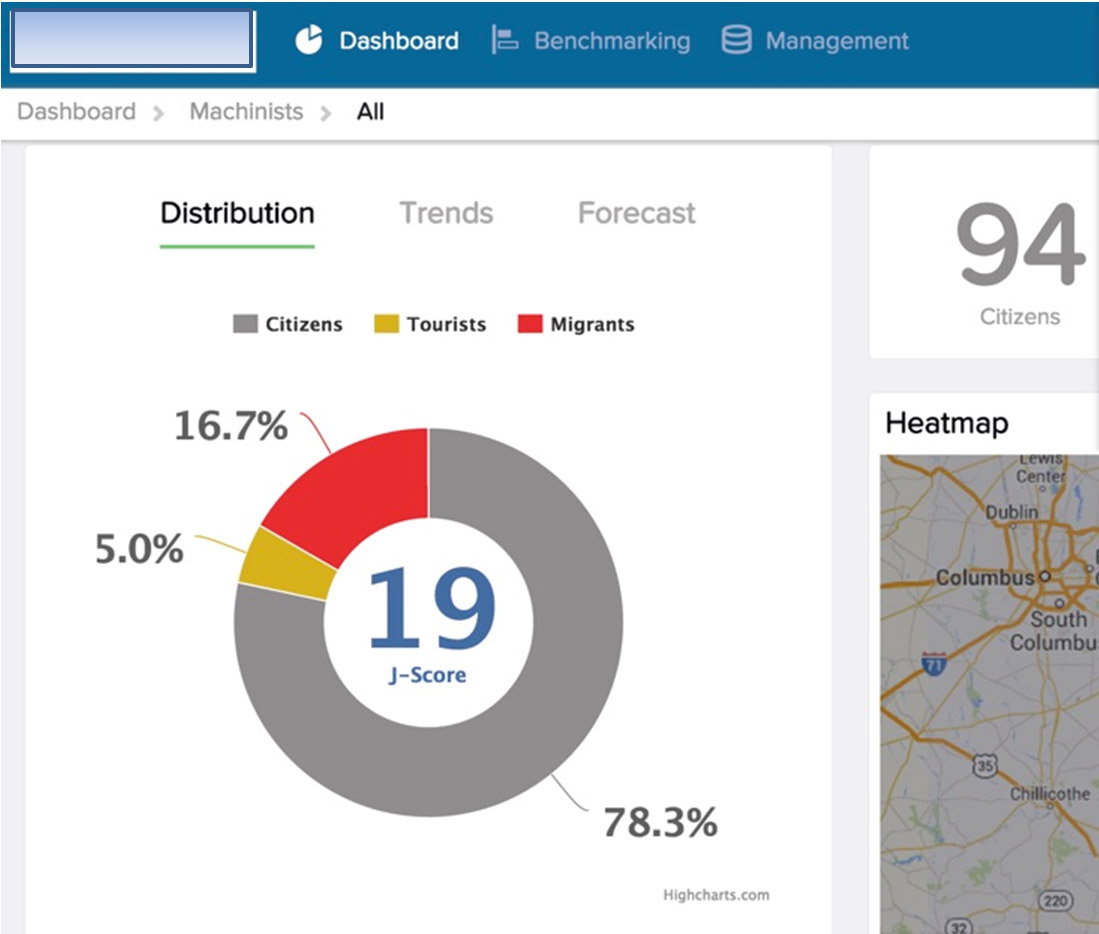
Dieser Wert wird dabei berechnet aus allen möglichen Datenquellen z.B. Social Networks: Welchen Personen folge ich bei Twitter, wer folgt mir? Mit wem habe ich mich in letzter Zeit bei LinkedIn vernetzt? Was sind das so für Leute, wem folgen die, wer folgt denen, mit wem sind diese vernetzt? Was sind Themen, über die ich schreibe (z.B. bei Twitter, nach Möglichkeit noch schön sortiert nach Hashtags) und bei welchen dieser Themen reagiert meine Followerschaft wie? Was retweete ich, was like ich, was kommentiere ich? Und auch – semantische Analyse lässt grüßen – was genau sage ich eigentlich inhaltlich?
Man kann diese Aufzählung endlos weiterführen. Im sog. Scoring, also der beinahe altbekannten Disziplin der Berechnung von Kreditwürdigkeit, werden z.B. Datenpunkte wie Anzahl laufender Ratenkredite oder Anzahl verfügbarer Kreditkarten berücksichtigt. Die Schufa hat im Schnitt pro Bundesbürger (im geschäftsfähigen Alter) etwa 12 solcher Datenpunkte. „Neue“ Anbieter auf diesem Markt wie etwa Kreditech oder Wonga berücksichtigen mehrere Hundert Datenpunkte und dabei eben auch solche Exoten wie „installierte Schriftarten“ oder „Modernität oder Preisklasse des Smartphones, mit dem der User im Internet surft“ usw.
D.h. also auch bei der Berechnung der Jobwechsel-Wahrscheinlichkeit können theoretisch unendlich viele, praktisch sicherlich mehrere Hundert Datenpunkte einbezogen werden.
Der Joberate J-Score reicht dabei von 4 bis max. 70, wobei 4 bedeutet: Keine Chance, wechselt quasi sicher nicht und 70 bedeutet: Der ist so gut wie weg. Auf dieser Basis teilt Joberate Personen in drei Typen ein:
- Citizens: „niedrige bis normale“ J-Scores. Hier liegt die Wechselwahrscheinlichkeit eher niedrig
- Tourists: „mittlere“ J-Scores. Man zeigt einzelne Aktivitäten und liebäugelt mit dem Fremden, ohne hier besondere Aktivität zu zeigen
- Migrants: „hohe“ J-Scores. Aktiv wechselwillig, was sich im Verhalten ausdrückt
Kommen wir zu Frage 1 von oben: Wofür soll das gut sein?
Interessant hierbei ist nun natürlich zum einen der Status-Quo:
Wie sieht das eigentlich jetzt gerade bei Person XY aus? Wenn man also z.B. im Executive Search oder Active Sourcing unterwegs ist und sieht, dass eine Person wechselwillig ist, dann kann man diese mit einer höheren Wahrscheinlichkeit (und ggf. erheblich niedrigerem Schmerzensgeld) zum Wechsel bewegen. Oder: Wenn man einen Mitarbeiter ohnehin ganz gern los werden möchte und sieht, dass dieser sowieso bei nächstbester Gelegenheit wechselt, muss man sich vielleicht kein teures Abfindungspaket überlegen…
Aber interessant ist natürlich vor allem die Veränderung des J-Score im Zeitverlauf:
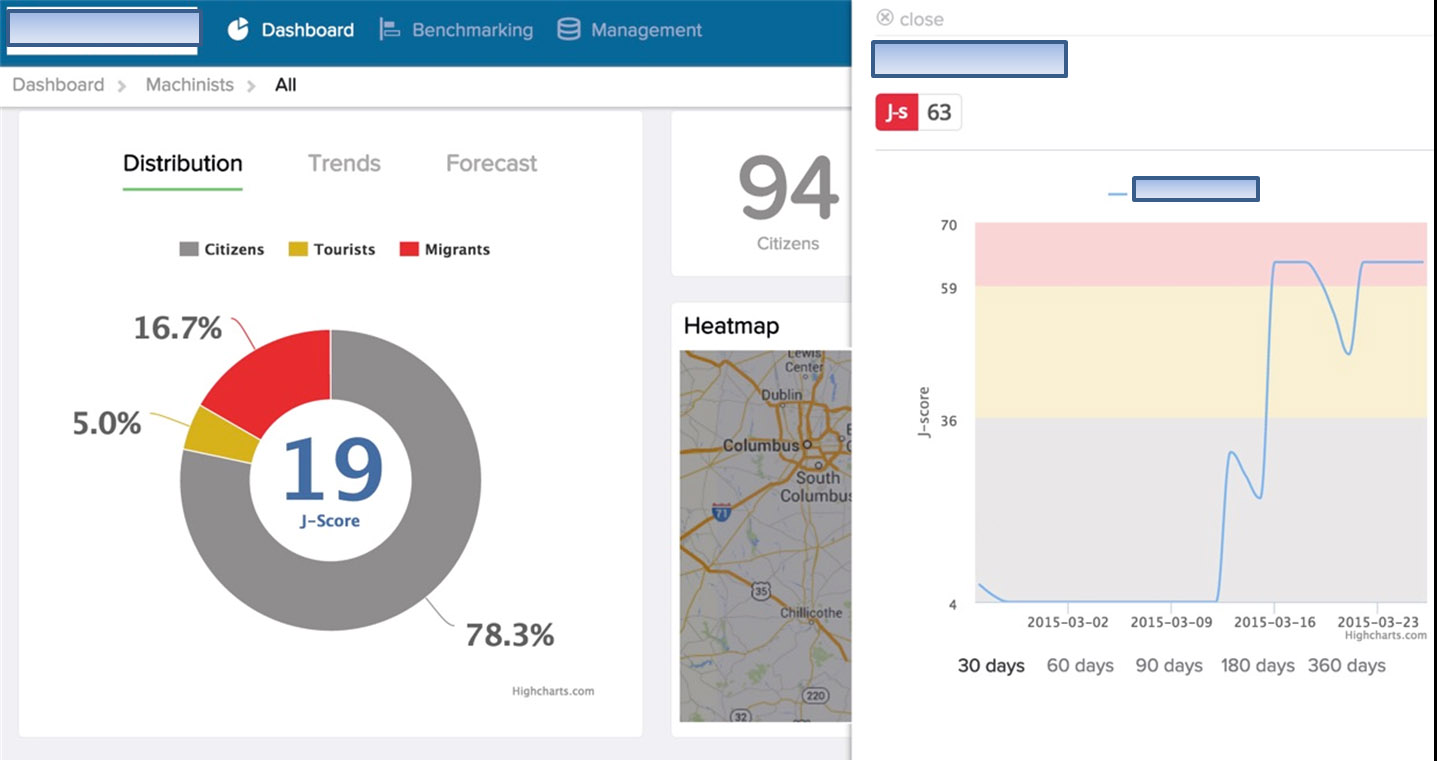
Jobwechsel-Wahrscheinlichkeit ist ja keine statische Größe, sondern diese verändert sich konstant. Und diese Veränderung drückt sich im Verhalten, und damit auch dem Datenspuren hinterlassenden Verhalten, aus. Wenn also nach dem aus Sicht des Mitarbeiters vielleicht unerfreulich verlaufenen Jahresgespräch auf einmal verschiedene Facebook-Karriereseiten aufgerufen und/oder gelikt werden, Kontakte mit Recruitern bei XING geknüpft werden oder bei amazon nach einem Bewerbungsratgeber gesucht wird usw., dann kann man das am steigenden J-Score ablesen. Wenn umgekehrt z.B. die Einführung eines Mindestlohns zu mehr Zufriedenheit führt, dann wird das in einem sinkenden J-Score münden.
Wofür das gut sein soll? Tja, zunächst mal drängen sich einem natürlich viele interessante Einsatzmöglichkeiten dieser Information in Bezug Retention-Fragestellungen auf, also rund um die Frage, wie eigentlich gute Mitarbeiter möglichst lange im Unternehmen (und nicht so gute möglichst eher nicht so lange…) gehalten werden können.
In diesem Zusammenhang ist dann nämlich auch der sog. J-Index zu sehen. Dabei handelt es sich im Prinzip um einen aggregierten J-Score für größere Einheiten, z.B. Abteilungen, Unternehmensbereiche oder ganze Unternehmen…
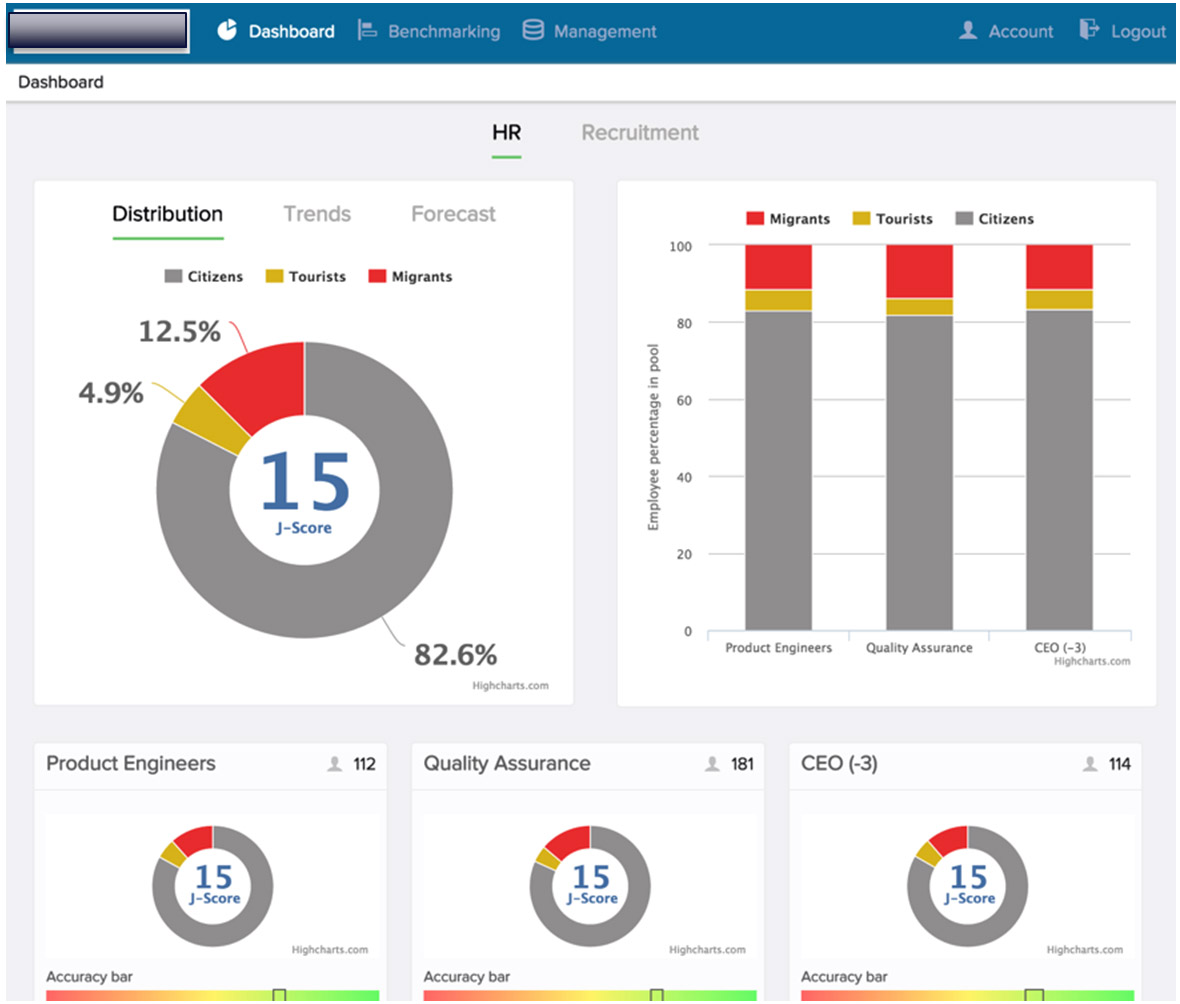
…wodurch dann z.B. Abteilungen…
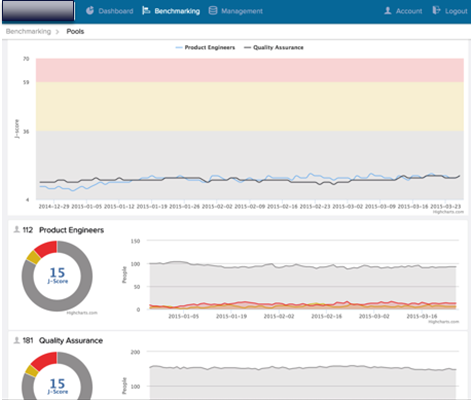
…oder Regionen, in denen die Mitarbeiter wohnen, verglichen werden können.
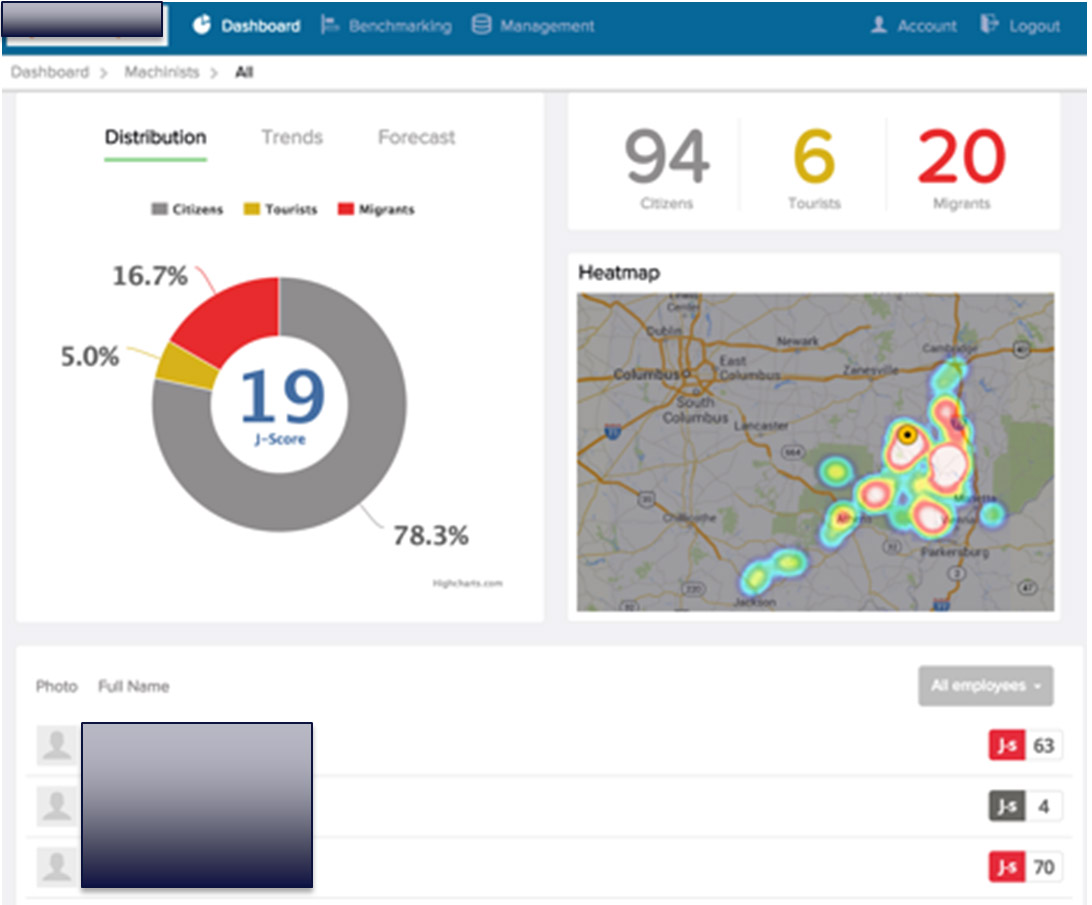
Neben den naheliegenden personalwirtschaftlichen Nutzen rund um die Retention-Frage können solche J-Indices dann natürlich auch noch sehr viele andere Fragen beantworten. Man könnte sich etwa vorstellen, dass es für Financial Analysts durchaus interessant ist, den J-Index börsennotierter Unternehmen zu verfolgen und damit einen Frühindikator für Employment Volatility und damit einen Börsenkurs beeinflussenden Parameter zu haben…
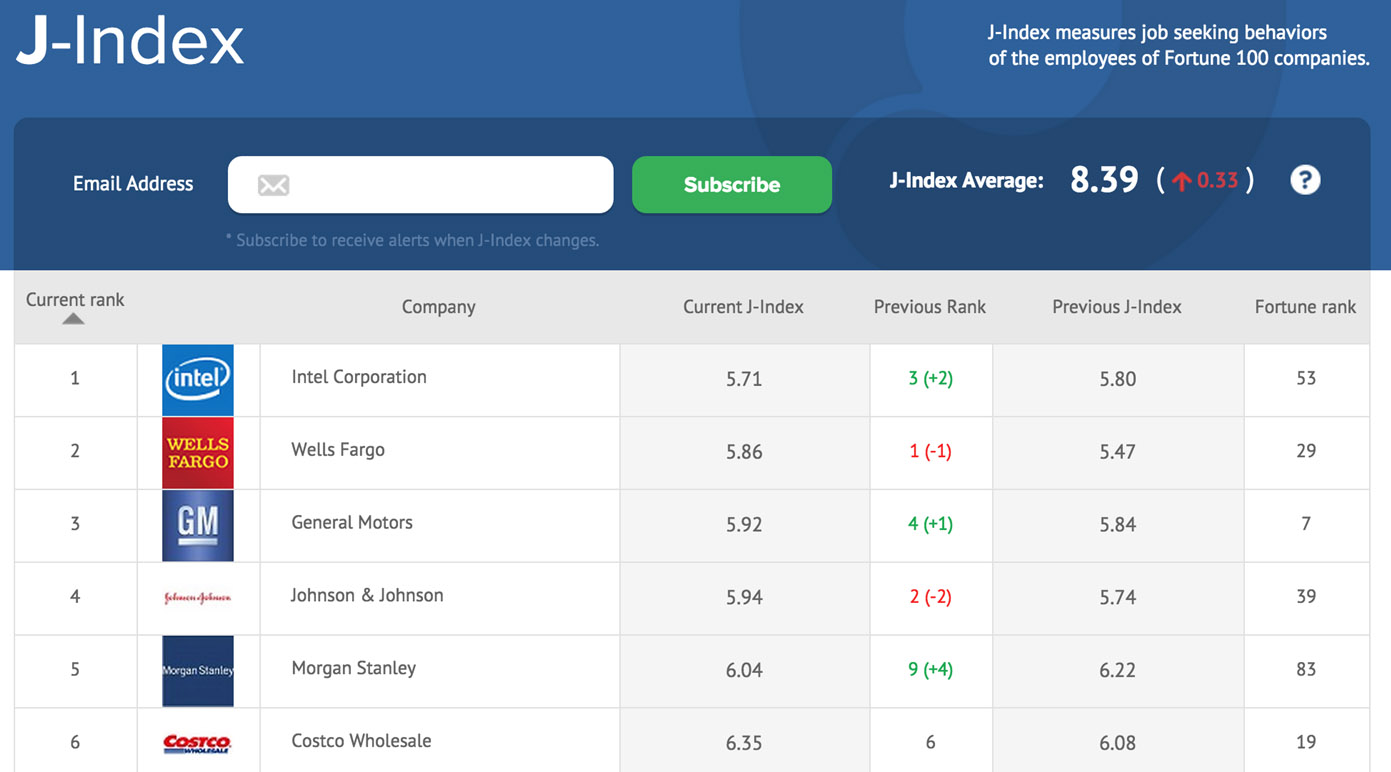
Das liefert sehr spannende Einblicke. So lag z.B. Wal-Mart in den USA immer relativ weit unten in dieser Liste (hoher J-Index = hohe durchschnittliche Wechselbereitschaft = niedrige durchschnittliche Job-Zufriedenheit der Belegschaft). Dann führte Wal-Mart einen Mindestlohn ein und zack sank der J-Index dramatisch). Man kann also durchaus die Auswirkungen personalpolitischer Maßnahmen nahezu unvermittelt ablesen.
Wer sich jetzt fragt, wie man an diese Informationen ran kommt, der kann sich gern bei Joberate melden. Man kann dabei eine webbasierte SaaS-Lösung kaufen oder sich den J-Score seiner Mitarbeiter oder potentieller zukünftiger Mitarbeiter direkt per Schnittstelle in seine TRM- bzw. BMS-Lösung oder Personalverwaltung liefern lassen…
Kommen wir abschließend zu Frage 2: Was steckt da für das Matching drin?
Nun, vordergründig ist Joberate erst einmal stärker mit dem Thema Retention verbunden, also der (unternehmensinternen) Frage, wie man seine Mitarbeiter (vor allem die guten natürlich) möglichst lange hält. Da ist die Frage nach der Wechselwilligkeit von Mitarbeitern oder Belegschaft als Ganzes natürlich sehr naheliegend. Dieser Retention-Fokus hat was mit der amerikanischen Herkunft von Joberate zu tun.
Mit den Eintritt in den deutschen Markt jedoch treten daneben auch andere Verwendungs- bzw. Einsatzformen in den Fokus. Wie oben kurz angedeutet, ist die Information, ob jemand jetzt gerade mehr oder weniger wechselwillig ist, natürlich ein unheimlich wertvoller Datenpunkt für Matching, also die Frage, ob er/sie der/die richtige ist. Und das gilt natürlich auch und insb. für unternehmensexterne Personen, also im passiven und vor allem aktiven Recruiting.
Man denke z.B. einmal an die Guerilla Recruiting Aktion der Deutschen Telekom vor ein paar Jahren, bei der vor den Konzernzentralen von Wettbewerbern Eis und Croissants verteilt wurden…

…Mal angenommen, die Telekom hätte im Nachgang dann nachschauen können, bei welchen Mitarbeitern dieser so „überfallenen“ Wettbewerber der J-Score sprunghaft ansteigt; nun man hätte einen wunderbaren Datenpunkt, um darauf basierend dann sehr gezielt abzuwerben aktiv zu sourcen…
Fazit:
Ja, zuweilen kriecht es einen schon an – das etwas ungute Gefühl, dass irgendwo im Verborgenen Dinge passieren mit unseren Daten, mit uns, die wir nicht mehr überblicken, kontrollieren oder steuern können. Darin stecken viele Chancen, weil eben die Maschine vieles ziemlich gut kann. Darin stecken natürlich auch Risiken. Ich habe hier ganz bewusst das Datenschutz-Fass nicht aufgemacht rund um die berühmten §§4 BDSG (Einwilligung) und 6a (automatisierte Einzelentscheidung) – das ist ein Thema vor allem für Ninas Blog – aber natürlich spielt es bei solchen Big Data-Themen wie bei Joberate eine wichtige Rolle.
Auch misshagt einem – speziell wenn man aus der Eignungsdiagnostik kommt – der postulierte Allmachtanspruch, den Big Data zuweilen verbreitet. Jeder der sich mit Datenanalyse beschäftigt weiß was Wahrscheinlichkeiten sind – und nichts anderes sind die Korrelationen, die bei Big Data herauskommen. Selbst wenn es eine Maschine also begründet für sehr sehr wahrscheinlich hält, dass ich gerade wechselwillig bin (weil sich eine wunderbare Gauß´sche Glockenkurve in den Daten gezeigt hat), kann es sein, dass es bei mir eben doch nicht stimmt (weil selbst eine perfekte Normalverteilung eben links und rechts Standardabweichungen hat).
Maximum-Likelihood ist nicht gleich Sicherheit
Sich allerdings auf den Standpunkt zurückzuziehen, dass das alles eh nicht rechtens sei, dass auch Maschinen fehlerhafte Einschätzungen liefern und das alles deshalb früher oder später eh wieder von allein verschwindet, wäre nicht anderes als naiv. Diese Dinge passieren und die Entwicklung ist nicht aufzuhalten. Bestenfalls ist die Richtung zu beeinflussen und das wichtigste dabei ist KENNTNIS!
Ich kann also wirklich jeden nur dringend ermuntern, sich mit diesen Themen zu befassen und nach Möglichkeit nicht aus falsch verstandener Nostalgie zu postulieren, dass „das Menschen besser können“. Auf der HR-Edge bietet sich die Möglichkeit, genau diese Fragen zu diskutieren (neben anderen spannenden „edgy“ Themen wie Unternehmenskultur, Augmented- und Virtual Reality oder Candidate Experience).
Ich würde mich sehr freuen, viele von Euch am 10. September in Hamburg begrüßen zu können.
Und naja, dass Roboter dann doch (noch) nicht alles (besser) können – dafür gibt es zum Abschluss noch ein kleines Schmankerl…
… und genau diese Wahrscheinlichkeiten erzeugen dann auch die Realität und prägen die Norm.
In Österreich sind derzeit fast 400.000 Personen arbeitslos gemeldet. Das ist ein Rekord, die Tendenz ist steigend. Der AMS Jobroom wurde vom AMS (Arbeitsmarkt Service) ins Leben gerufen, und bietet über 50.000 freie Arbeitsplätze in Österreich an. Meine Website vermittelt kostenlose Tipps und einen Bewerbungs-Ratgeber für Jobsuchende. Alles Gute, Euer Tomas