
Nein, der Titel dieses Beitrags soll nicht abschrecken, auch wenn er ganz schlimm nach Statistik-Vorlesung klingt… Im Gegenteil: Eigentlich handelt es sich eher um eine Art Fundstück und kommt daher aus der unterhaltsamen Ecke.
Ich möchte Euch gern die Website „Spurious Correlations“ des Amerikaners Tyler Vigen vorstellen. Dieser sammelt darauf Beispiele für Scheinkorrelationen, also „Zusammenhänge zwischen Dingen, die zwar statistisch unglaublich hoch sind, aber in Wahrheit natürlich nicht existieren“.
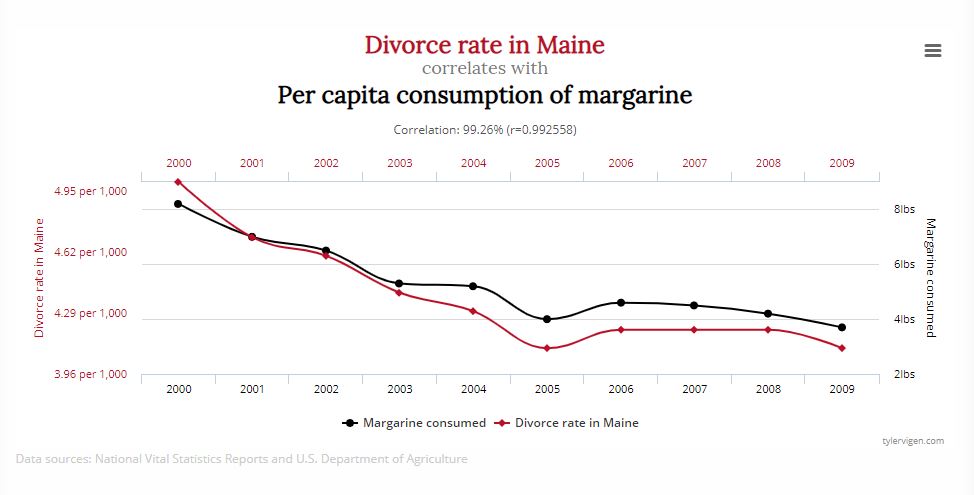
Man findet da so kuriose Dinge wie den Zusammenhang zwischen der Scheidungsrate im US-Bundesstaat Maine und dem Pro-Kopf-Verbrauch von Margarine (r=.992)…
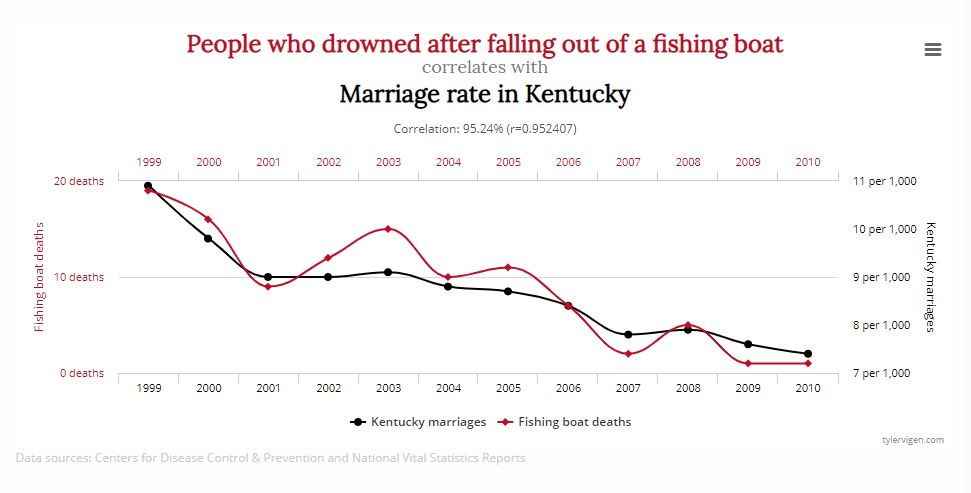
…oder zwischen der Heirats-Rate in Kentucky und der Zahl an Ertrunkenen, die aus einem Fischerboot gefallen sind (r=.952).
Mein All-Time-Favorite bleibt aber immer noch der Zusammenhang zwischen den US-Forschungsausgaben und der Zahl an Selbstmorden durch Erhängen, Strangulieren oder Ersticken (r=.998).

Bei seinem Kreuzzug gegen die Wissenschaft hat der US-Präsident mit orangem „Haar“ also ganz sicher nur Gutes im Sinn: Er senkt die Forschungsausgaben, um die Zahl an Selbstmorden zu reduzieren!
Und genau an dieser Stelle kommen wir zum ernsten Hintergrund dieser Thematik.
Wir leben in einer Zeit, von der es heißt: Daten regieren die Welt. Oder: Daten sind das Gold des 21. Jahrhunderts.
Nun, da ist ganz sicher auch einiges dran. Unternehmen, deren Geschäft es ist, Informationen zu makeln („Plattform-Ökonomie“) gehören zu den wertvollsten der Welt. Ihr alle kennt die Beispiele von „Airbnb = größtes Übernachtungsunternehmen der Welt, ohne ein einziges eigenes Hotelbett“ oder „uber = größtes Taxiunternehmen ohne eigenes Taxi“ usw. Der Wert steckt in den Daten, in der Kenntnis der Zusammenhänge…
Und Daten sind die Grundlage für Algorithmen. Aus der Kenntnis von Zusammenhängen werden Automatismen gemacht. Und diese Automatismen werden zunehmend in die Hände von Maschinen gelegt. Übertragen auf das Recruitinggeschäft läuft das dann oft stark vereinfachend unter dem Schlagwort „Robo-Recruiting“ – im Moment ist ja alles irgendwie „künstliche Intelligenz“…
Eigentlich muss man aber immer mit etwas Demut von der „vermeintlichen“ Kenntnis von Zusammenhängen sprechen. Denn allzu oft handelt es sich nämlich nicht um tatsächliche Zusammenhänge, sondern letztlich um vollkommen unerklärbare Zufälle – siehe oben. Zweitens handelt es sich zunächst mal nur um Korrelationen, d.h. der simplen Frage, wie sehr eine Sache auftritt, wenn auch eine andere Sache auftritt. Über den Grund des Zusammenhangs („warum tritt das eine auf, wenn das andere auftritt?“), die Ursächlichkeit („das eine tritt auf, weil das andere auftritt“) oder gar die Wirkungsrichtung („das eine führt zum anderen, aber nicht umgekehrt“), darüber sagt eine Korrelation zunächst einmal nichts aus.
Das ist aber ein Grundübel, das im Kern in Big Data steckt. Heute, wo die Rechnerleistungen endlich in der Lage sind, auch immens große, vor allem auch unstrukturierte, Datenmengen nach Zusammenhängen und Muster durchsuchen zu können, lässt man sie auch genau dies tun. Das ist auch richtig so, zeigt sich doch das Big Picture oft auch wirklich erst, wenn man von weit weg drauf schaut. Aber es birgt eben auch die Gefahr, dass man den zweiten eigentlich viel wichtigeren Teil der Arbeit vernachlässigt – den der Interpretation.
Hier bekommt nämlich noch ein zweiter relativer basaler statistischer Effekt eine große Bedeutung: Die Signifikanz.
Ihr kennt das sicher alle, wenn jemand mal wieder davon spricht, dass ein Zusammenhang „signifikant“ ist. Die wenigsten wissen, was das eigentlich bedeutet, aber es taugt hervorragend als Totschlagargument. Wenn es „signifikant“ ist, dann ist es gleichsam wahr. Das Gemeine daran: Das stimmt auch irgendwie. Ist aber trotzdem komplett falsch.
Signifikanz heißt: Der Unterschied zwischen zwei Merkmalen ist wahrscheinlich nicht zufällig aufgetreten.
Das Zauberwort ist wahrscheinlich! Man überprüft mit sog. Signifikanztests die Hypothese, dass es keinen Zusammenhang zwischen zwei Merkmalen gibt. Dabei überprüft man die Wahrscheinlichkeit, dass man mit dem Verwerfen dieser Hypothese einen Fehler begeht. Und wenn diese Wahrscheinlichkeit unter einem gewissen Signifikanzniveau liegt, dann kann man die Hypothese ablehnen = es gibt einen Zusammenhang, der nicht zufällig ist.
Ist gemein, weiß ich. So viele doppelte Negationen. Und das am Freitag… Gut, müsst Ihr nicht im Detail verstehen. Wenn hängen bleibt, dass Signifikanzaussagen letztlich auch nur Wahrscheinlichkeitsaussagen (und keine Wahrheiten) sind, dann ist schon viel gewonnen.
Wichtiger ist nämlich noch etwas anderes: Je größer die Stichprobe (=Datenmenge), desto leichter wird ein gemessener Zusammenhang signifikant!
Das will ich jetzt nicht im Detail erklären (kann man hier nachlesen), aber die Aussage an sich muss man sich mal auf der Zunge zergehen lassen. Denn bei „Big Data“ sind die Datenmengen ja per Definition groß. D.h. es ist auch viel leichter signifikante (und damit wahrscheinlich nicht zufällige) Zusammenhängen zu finden.
Und so kann man dann auch „signifikant“ beweisen, dass Liebhaber von Curly Fries eben intelligenter sind als Menschen, denen gerade Stängelpommes ausreichen…
Versteht mich nicht falsch: Die Analyse von Daten ist enorm wichtig, auch und gerade im Recruiting. Wir haben uns hier viel zu lange ausschließlich auf menschliche Intuition und Bauchgefühl verlassen. Dass es nun endlich ernsthafte Bestrebungen in Richtung Recruiting Analytics und Data Driven Recruiting gibt, ist auf jeden Fall begrüßenswert.
Aber (und damit komme ich auch zum Ende und entlasse Euch ins Wochenende): Das heißt auf gar keinen Fall, dass wir uns dann jetzt alle zurücklehnen können, weil jetzt der schlaue Algorithmus, „basierend auf Big Data und den neuesten Erkenntnissen der Neuro-Forschung“ den Job übernimmt. Das geht sogar bei denen in die Hose, denen man wahrscheinlich mit die größte momentan auf der Welt anzutreffende Kompetenz bei der Analyse von Daten und Entwicklung entsprechender Algorithmen unterstellen darf (siehe Amazon).
Also, liebe Recruiter: Schön weiter die Hausaufgaben machen (und vielleicht auch mal wieder eine Vorlesung in Statistik besuchen…). #TGIF