
Wir haben zwar schon den 10. Januar, aber ich finde man kann trotzdem noch ein frohes neues Jahr wünschen. Ich habe gut zwei Wochen Blog-Pause eingelegt. Zum einen gab es auch so einiges zu tun, zum anderen musste ich auch ein paar Eindrücke und Gedanken aus dem alten Jahr für mich nochmal ein wenig sortieren.
Nach der KI ist vor der KI…
Wie der letzte Blogartikel von kurz vor Weihnachten bereits andeutete, bin ich mir sicher, dass 2019 – noch viel mehr als 2018 – unter der Überschrift Künstliche Intelligenz stehen wird. Allerdings, so meine Hoffnung, wird der teilweise blinde Aktionismus in der Berichterstattung, der wahlweise nur unreflektierte Euphorie oder Fundamentalopposition kannte, nun einer differenzierteren Sicht weichen.
So finde ich es persönlich z.B. sehr begrüßenswert, das der Bundesverband der Personalmanager einen „Ethikbeirat HR Tech“ ins Leben ruft, um (u.a.) den Nutzen künstlicher Intelligenz ethisch auszuloten. Denn neben der technischen Dimension gehören auch und vor allem methodische, juristische und eben ethische Aspekte ganz oben auf die Agenda. In dem Zusammenhang durchaus bemerkenswert war etwa die Meldung, dass Google seine Gesichtserkennungssoftware vorerst nicht freigeben möchte, solange die damit einhergehenden ethischen Fragen nicht weitergehend geklärt sind…
Nun wie gesagt, ich glaube man wird auch genau davon so einiges zu hören und zu lesen bekommen in diesem Jahr, denn KI macht keinen Sinn, wenn sie nichts taugt, man sie nicht einsetzen darf oder man sie nicht einsetzen sollte…
So, bei dieser Vorrede ist es daher auch nicht sonderlich überraschend, dass der Recrutainment Blog nicht nur 2018 mit einem KI-Beitrag beendet, sondern auch 2019 mit einem eröffnet. Es geht heute um das Thema Deepfakes…
Was sind Deepfakes?
Nun, wir leben in Zeiten von Fake News und Alternativen Fakten. Jeder lebt in seiner eigenen – durch Social Media und deren Algorithmen zusätzlich verstärkten – Filterblase. Damit lebt jeder irgendwie auch in seiner eigenen Welt und glaubt auch nur noch seiner eigenen Wahrheit. Hier auszubrechen, auch andere Meinungen wahrzunehmen, ist eine der ganz großen Herausforderungen unserer Zeit.
Doch was, wenn man – auch mit großer Mühe – schlichtweg nicht mehr erkennen kann, ob eine Nachricht stimmt oder nicht? Was, wenn man hierbei den eigenen Augen und Ohren nicht mehr trauen kann?
Dieses Problem wird uns durch sog. Deepfakes zukünftig in dramatischer Weise beschäftigen – und das potentiell auch im Recruiting, doch dazu unten mehr.
Deepfakes sind falsche, aber täuschend echt wirkende Bilder oder Videos.
Das Kunstwort setzt sich dabei zusammen aus Fake und Deep, wobei das Deep schon andeutet, dass es was mit künstlicher Intelligenz, in diesem Fall mit künstlichen neuronalen Netzen – mit Deep Learning – zu tun hat. Die Inhalte sind nämlich maßgeblich durch KI erzeugt bzw. von dieser manipuliert.
Ich würde den Begriff auch noch ausdehnen auf falsche, aber täuschend echt wirkende Audioinhalte, denn sowohl die Technologien als auch die Auswirkungen sind diesbzgl. ähnlich zu bewerten.
Nun, sowohl bzgl. (Bewegt-)Bild auch bzgl. Audio ist das nichts prinzipiell neues. Hollywood macht das schon lange. Was neu ist: Dank KI kann das bald jeder, sofern er ein bisschen Rechnerleistung dafür über hat und entsprechendes Bildmaterial, mit dem die KI trainiert werden kann.
Das Thema ist spätestens Ende 2017 in der Diskussion angekommen, weil damals ein anonymer Reddit-Nutzer unter dem Pseudonym „Deepfakes“ mehrere Pornovideos ins Internet stellte, die verschiedene bekannte (seriöse) Schauspielerinnen wie Emma Watson oder Scarlett Johansson beim Sex zeigten. Vermeintlich. Denn die Szenen waren nicht echt, sondern unter Verwendung künstlicher Intelligenz erstellt worden.
Gut, ich werde jetzt hier diese Videos NICHT zeigen, aber ein Blick in das folgende Youtube-Video zeigt schon ziemlich beeindruckend, wie gut sich echte Bilder manipulieren lassen. Und in diesem Fall handelt es sich sogar um die Manipulation von Bewegtbild in Echtzeit (!) – sog. Real-Time Reenactment.
Wer hier tiefer einsteigen will, der kann hier ein paar Hintergründe zu dem Forschungsprojekt Face2Face der Unis Nürnberg-Erlangen und Stanford sowie dem Max Planck Institut für Informatik nachlesen.
Dass das ebenso mit Sprache geht, zeigt wunderbar folgendes Video auf, dass die Adobe Software #VoCo beschreibt:
#VoCo – manchmal auch als Photoshop-for-Voice bezeichnet – arbeitet hierbei nicht wie frühere Sprachgeneratoren, indem es Worte und Laute einer Person aneinanderreiht (und dabei bestenfalls noch die Übergänge glättet), sondern indem es die Sprache einer Person komplett synthetisiert und dann daraus im Prinzip dann wieder in beliebiger Form zusammensetzt. Als Ausgangsmaterial braucht die Software daher auch nicht Tausende von Worten und Lauten eines Sprechers (wie das z.B. für die Sprachansagen in Navigationssystemen oder in Sprachmenüs gemacht wird), sondern nur irgendeine etwa 20-minütige Sprachprobe einer Person, die sich wahrscheinlich vergleichsweise einfach von jedem beliebigen „Opfer“ beschaffen lässt.
Kurz zusammengefasst: Man kann also offenbar echte Menschen im Prinzip tun und sagen lassen, was man will. Das entsprechende Kopfkino (was ist wenn Donald Trump nachher über die Bildschirme flimmert und verkündet, Nordkorea den Krieg erklärt zu haben…?) kann dabei ja jetzt jeder selber einmal anschmeißen…
Wie funktionieren Deepfakes?
Zunächst mal braucht man Ausgangsmaterial (an Bewegtbildinhalten) der Personen, die man faken will, d.h. zum Beispiel der Person, die man in ein anderes Video integrieren will. Je mehr Ausgangsmaterial desto besser und wenn dieses Ausgangsmaterial die Person gleich auch noch aus mehreren Perspektiven (von vorn, von der Seite, lachend, sprechend etc.) zeigt, um so besser.
Speziell bei Personen, die in der Öffentlichkeit stehen, gibt es solches Ausgangsmaterial natürlich in rauen Mengen. Aber auch von Normalos gibt es oft mehr als ausreichend verwendbares Material, sei es weil jemand mal hier oder da einen Vortrag hält (und dabei gefilmt wird), video-podcasted oder einfach sehr lax im Umgang mit seinem eigenen Bild in Social Media ist…
Das folgende Video bspw., bei dem ein US-Late-Night-Talker (John Oliver) in die Rolle eines anderen US-Late-Night-Talkers (Jimmy Fallon) schlüpft, entstand aus ca. 15.000 Bildern pro Person.
Wer jetzt denkt, „ach 15000 Bilder? So viele gibt es von mir nicht im Netz!“ dem sei gesagt: Eine Sekunde Video sind schon 20 bis 30 Bilder. Ein 2-minütiges Video-Interview, das bei Youtube zu sehen ist, sind schon 2400 Bilder… Und reichen tun schon erheblich weniger Bilder (ca. 300), um manierliche Ergebnisse zu erzielen.
Mit diesem Material wird dann trainiert. Das dauert je nach Menge an Ausgangsmaterial und Leistungsstärke des Prozessors einige Stunden. Okay, das kann auch einige Tage dauern, aber man muss in der Zeit nichts tun – man lässt die KI einfach trainieren, trainieren, trainieren…
Was passiert da genau? Wie funktioniert die Magie?
Im Kern eines solchen Deepfakes Codes steht der sog. Autoencoder. Dieses neuronale Netz nimmt sich soz. ein Ausgangsbild und zerlegt es in eine digitales Abbild (ein „encoding“). Dieses Abbild wiederum versucht nun wiederum, das eigentliche Ausgangsbild künstlich zu erzeugen (zu „decoden“). Hierbei gibt man möglichst viel und möglichst unterschiedliches (und gern auch bewusst verzerrtes Bildmaterial) ins Encoding und lässt die Maschine ordentlich strampeln um per Decoding wieder ein möglichst dem Ausgangsmaterial ähnliches Ergebnis zu erzeugen.
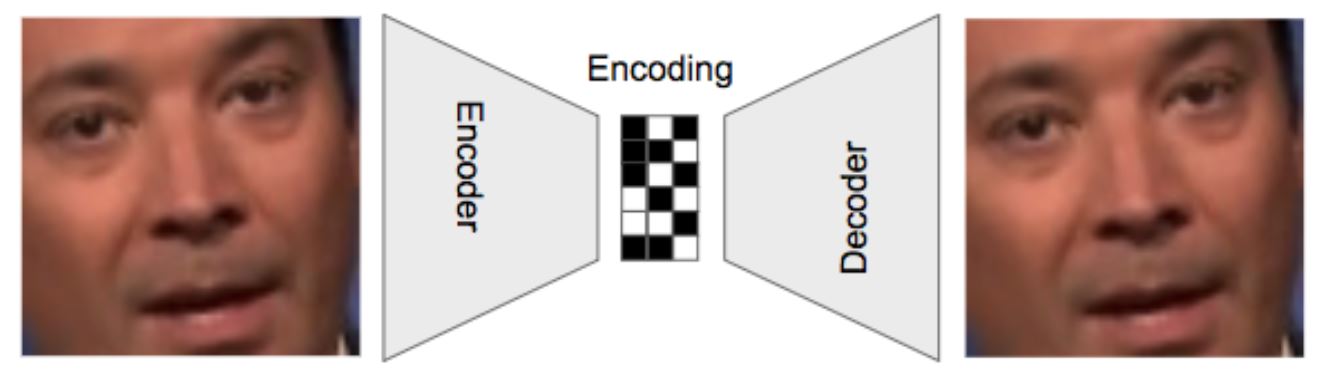
(Image by @goberoi)
Das gelingt im Zeitverlauf immer besser bis irgendwann die Unterschiede zwischen Ausgangsmaterial und Ergebnis nur noch sehr gering sind (also „wenig Information“ verloren geht, ausgedrückt durch den sog. „Loss-Wert“).
Will man nun zwei Personen „swappen“, dann macht man das entsprechend mit zwei Personen. Wichtig dabei: Es gibt nur einen Encoder, aber zwei Decoder. Hierbei wird im Training zunächst Bildmaterial von Person 1 encoded und mit Hilfe des Decoders A wieder zu einem Abbild von Person 1 decoded und Bildmaterial von Person 2 (mit dem gleichen Encoder) encoded und mit Hilfe des zweiten Decoders B wieder zu einem Abbild von Person 2 decoded.
Das macht das neuronale Netz nun sehr oft, so dass der Decoder A lernt, aus ganz viel verschiedenem Ausgangsmaterial ein möglichst gutes Abbild von Person 1 zu erzeugen. Und Decoder B lernt das für Person 2.
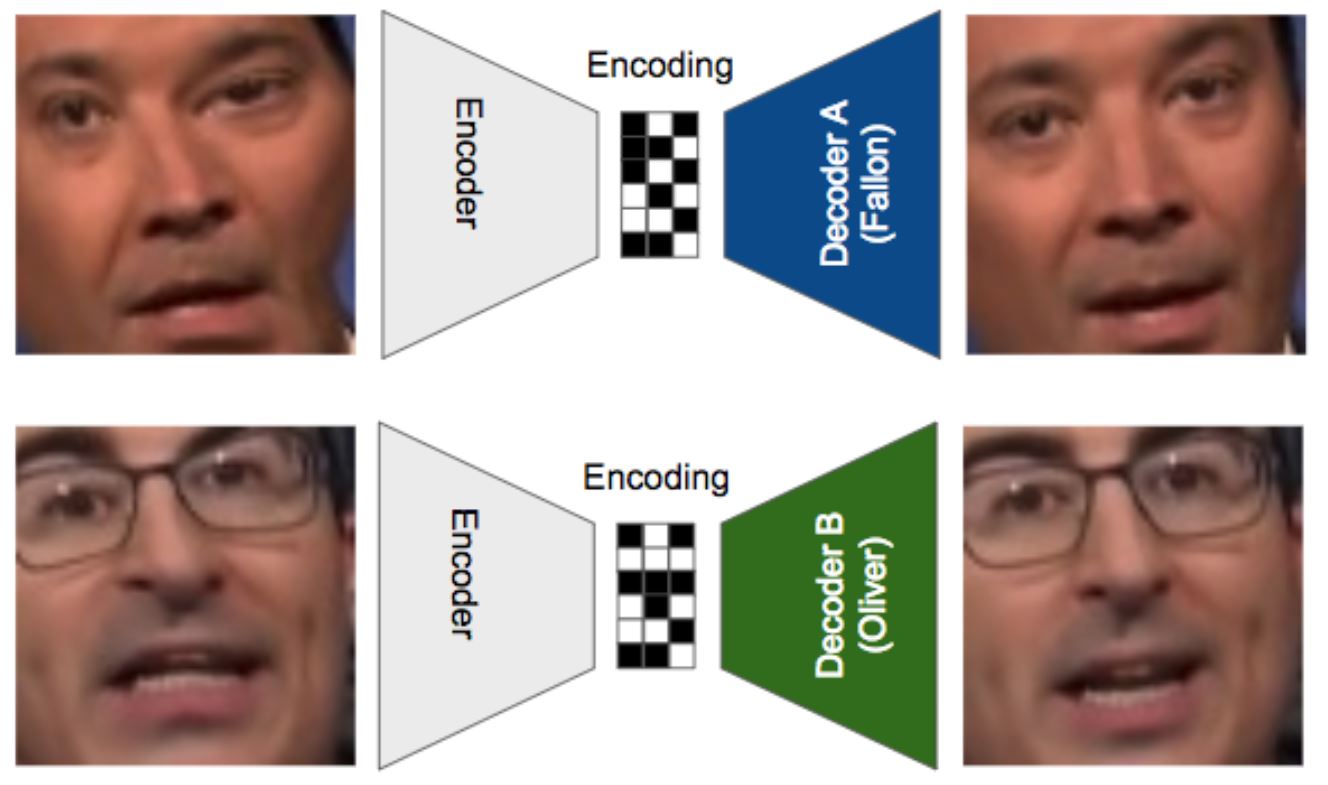
Und jetzt kommt der simple wie geniale Trick:
Nun wird Bildmaterial von Person 1 in den Encoder gejagt, aber anstatt (mit Hilfe des Decoders A) daraus wieder ein Abbild von Person 1 zu erzeugen, soll die Maschine (mit Hilfe des Decoders B) daraus ein Abbild von Person 2 schaffen.
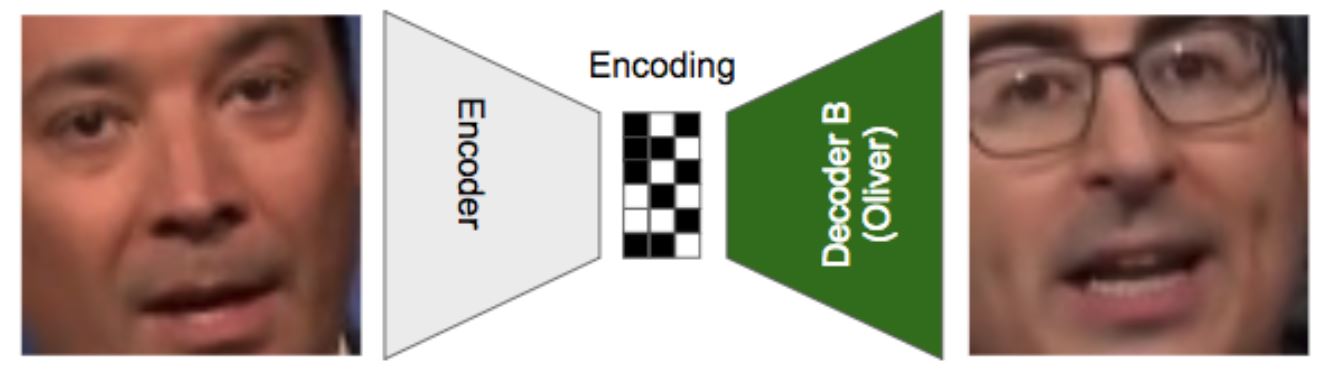
Man kann es so ausdrücken: Der Encoder versteht irgendwann die Essenz, die wesentlichen Merkmale des Bilds von Person 1, gibt es an den Decoder B und der sagt „oh ja, wieder verzerrtes Bildmaterial, aber ich habe ja gelernt daraus ein Abbild von Person 2 zu erzeugen“… Und so macht die KI aus Ausgangsmaterial von Person 1 wunderbares Fake-Material von Person 2.
Perspektivisch ein großes Problem für das Recruiting…
Scary oder? Ich meine, jeden Menschen im Prinzip tun und sagen lassen zu können, was man will. Wem oder was soll man dann noch glauben?
Und natürlich bedeutet dies auch perspektivisch ein großes Problem für das Recruiting. Viele der aktuell hochgehandelten Themen im Recruiting handeln z.B. von der automatisierten Analyse von (gesprochener) Sprache (Precire), (geschriebener) Sprache (100Worte) oder Video (HireVue). Was aber soll diese Analyse über die „Person“ des Bewerbers aussagen, wenn das analysierte Datenmaterial gar nicht von der Person selber stammt, sondern von einer KI erzeugt wurde? Was bringt die „Deutung“ von Prosodik, Phonemen, Sprechgeschwindigkeit, Wortdichte, Verwendung von Füllwörtern, Mimik, Gestik oder sogar des semantischen Inhalts, wenn all das gar nicht vom Kandidaten selber stammt, sondern von einer Maschine?
Klar, momentan ist die Produktion von Deepfakes noch vergleichsweise aufwendig. Jemand, der sowas kann, nun den würde ich als Unternehmen auf jeden Fall einstellen… ;-) Aber das wird ja nicht so bleiben – entsprechende Software wird über kurz oder lang für jedermann verfügbar sein (also Software, die über das was FakeApp kann hinausgeht…). Jeder wird von sich selber (oder anderen!) Videos oder Sprachproben erzeugen können, die so designt sind, wie der Manipulator es möchte.
Und das führt den Nutzen von Systemen, die automatisiert aus Bewegtbild oder Sprechproben Dinge über den Darsteller / Sprecher ableiten wollen, im Prinzip ad absurdum.
Die einzigen Auswege aus diesem Dilemma:
Unternehmen werden gezwungen sein, noch weiter aufzurüsten und selber wiederum (forensische) KI einsetzen, die (hoffentlich) in der Lage ist, „Fake-Bewerbungsmaterial“ auch als solches zu enttarnen. Wir wären wieder bei unserem „Rattenrennen„… Möglicherweise könnten auch „Verification-Stempel“ in der Blockchain hinterlegt werden, die nicht mehr verändert werden können. Das ist aber – wie das allermeiste aus der Blockchain-Welt – noch ziemlich weit draußen…
Und: Um zu verhindern, dass Bewerber „auf den Zweck hin designte“ Bewerbungsinhalte schicken, muss das Bewerbungsverfahren „unvorhersehbar“ sein. D.h. die Fragen, die in einem Videointerview gestellt werden, die Merkmale, nach denen eine Sprachprobe ausgewertet wird usw., dürfen nicht vorher bekannt sein. Das wiederum widerspricht aber dem Automatisierungsgedanken, der ja letztlich einer der Haupttreiber der Entwicklung an sich ist.
Nun, wir werden das hier und heute natürlich nicht abschließend beantworten können, aber je mehr Leute mit darauf herumdenken desto besser…
In diesem Sinne: Lasst Euch keine (Deep-)Fakes unterjubeln und glaubt nicht alles, was man euch erzählt Ihr seht…
Auf ein spannendes 2019!
P.S. Special Kudos to Gaurav Oberoi who did the job of swapping John Oliver´s and Jimmy Fallon´s head in video and describing this in simple words on kdnuggets.com.
Tja, die Zeit ist gekommen, in der das persönliche Gespräch wieder die höchste Validität aufweist ;-)
Danke für den spannenden Einblick!