
Dauert es noch fünf oder gar zehn Jahre, bis der “klassische Recruiter” vom Roboter ersetzt wird? Oder wird schon 2017 den Durchbruch bringen? Wollen wir das überhaupt? Und sollten wir es überhaupt wollen?
Ich hole dazu “ein wenig” aus…
Algorithmen greifen nach der Weltherrschaft
Vor ein paar Wochen, genauer gesagt um den 3. Dezember herum, schwappte eine große Welle Aufregung durchs Netz. Anlass und Auslöser hierfür war ein Artikel, der im “Magazin”, einer Beilage des Schweizer Tagesanzeigers, erschien.
In dem Beitrag “Ich habe nur gezeigt, dass es die Bombe gibt” wurde eine vermeintliche Erklärung für den für viele nach wie vor so unerklärlichen Wahlsieg Donald Trumps im Rennen um die amerikanische Präsidentschaft geliefert. In Kurz: Ein polnischer Psychologe entwickelt im Cavendish Lab, dem Zentrum für Psychometrie der englischen Cambridge Universität, eine Methode, die auf Basis des in Facebook an den Tag gelegten Verhaltens valide auf die Persönlichkeitsstruktur der jeweiligen Person schließen lässt. Diese Methode wird daraufhin von einer Firma namens Cambridge Analytica geklaut übernommen und im amerikanischen Wahlkampf eingesetzt, um sog. Microtargeting in bislang ungeahnter Präzision anzuwenden. Hierbei werden Personen in den Sozialen Netzwerken so gezielt mit auf sie abgestimmten Botschaften angesprochen, dass sie am Ende gar nicht anders können und das Undenkbare doch möglich und Donald Trump zum 45sten Präsidenten der USA machen.
Nach der ersten Aufregung, die man wahrscheinlich überschreiben kann mit “Oh Gott, jetzt ist es soweit, wir werden also alle manipuliert” dauerte es nicht lange und die Welle schwappte in die andere Richtung.
Dennis Horn schrieb – sinngemäß – in seinem Beitrag “Hat wirklich der große Big-Data-Zauber Trump zum Präsidenten gemacht?” im WDR-Blog, dass wir uns doch bitte nicht einerseits über Fakenews und unreflektiertes Wiedertröten selbiger echauffieren sollen, um dann bei nächstbester Gelegenheit (wie dem Beitrag aus dem “Magazin”) genau dieses wieder zu tun.
Stefan Winterbauer legte bei Meedia dann kurze Zeit später nach und machte aus der Story eine “linke Verschwörungstheorie”, die wenngleich möglicherweise moralisch genehmer, inhaltlich aber letztlich genauso bedenklich wie Fakenews vom rechten Rand seien.
Der Algorithmus also eine Fakenews? Eine Verschwörungstheorie?
Stimmen, die sich etwas weniger aufgeregt dafür aber differenzierter mit der Angelegenheit befasst haben, wurden leider in dieser ganzen Mikrohysterie übertönt. Dabei sind es doch genau diese, die vielmehr gehört werden sollten. Denn die Thematik – was können Algorithmen denn heute schon? Was werden sie können? Wo liegen Chancen, wo Risiken? – muss dringend auf den Tisch und sachlich betrachtet werden.
Als ich den Artikel im “Magazin” las, noch mehr bei der anschließenden Aufgeregtheit, musste ich ein wenig schmunzeln. Wir haben hier im Blog schon vor mehr als zweieinhalb Jahren mal einen recht ausführlichen Artikel über das Projekt “You are what you like” der – ja genau der – Cambridge Uni geschrieben. Mittlerweile läuft das ganze unter “Apply Magic Sauce” und es handelt sich um eben jene Forschung, um die es auch in dem eingangs erwähnten Artikel ging.
Ich gebe zu, uns ging es damals nicht um politische Werbung, uns ging es noch nicht einmal um Marketing oder Produktwerbung. Nein, unser Blickwinkel war der der Diagnostik im Recruitingkontext: Wir haben einmal kritisch durchleuchtet, ob sich möglicherweise mit Hilfe der Algorithmen aus Social Media Profilen Möglichkeiten ergeben, etwaige Bewerber valide zu beurteilen.
Unser Fazit – zumindest bzgl. des Projekts “You are what you like” – fiel seinerzeit noch etwas verhalten aus. Allerdings weniger, so unser Eindruck, weil es nicht ginge, aus den in Social Media enthaltenen Informationen valide auf Persönlichkeitsmerkmale zu schließen – das schien damals schon ganz manierlich zu funktionieren -, sondern vielmehr weil es anschließend so unheimlich schwierig ist, aus der gewonnenen Erkenntnis über die Persönlichkeit eines etwaigen Bewerbers auf dessen Arbeitsleistung zu schließen.
Um mal auf den “Magazin”-Artikel und den anschließenden Rummel zurück zu kommen:
Es ist also keineswegs Science Fiction (auch keine Fakenews und erst recht keine “Verschwörungstheorie”), wenn jemand behauptet, aus dem Click- oder “Like”-Verhalten von Menschen in den sozialen Medien auf deren Persönlichkeitsstruktur schließen zu können.
Im Gegenteil: Je größer die Datenbasis (die ist z.B. bei Facebook ziiiemlich groß) und je weniger “verunreinigt” die Daten (“Verunreinigung” im hier gemeinten Sinne entsteht etwa dadurch, dass Nutzer durch entsprechende Privatsphäre-Einstellungen nur Teile ihrer Daten sichtbar machen, andere nicht), desto besser wird dies gelingen.
Aber:
Nur weil ich weiß, dass jemand soundso extrovertiert, neurotisch, gewissenhaft, verträglich oder offen ist, heißt das noch lange nicht, dass ich diese Person beliebig in meinem Sinne manipulieren kann. Derartiges Geheimwissen wird Psychologen zwar häufig unterstellt, es ist aber Humbug. Dass es hier immense Unschärfen gibt, weiß die Eignungsdiagnostik nur allzu gut und zwar weil sie sich seit Jahrzehnten genau hiermit befasst. Die Wahl in den USA wurde durch diesen Algorithmus genauso wenig entschieden, wie durch den Einsatz von Gamification (was übrigens auch behauptet wurde…).
Man muss festhalten: Der Beitrag im “Magazin” ist wahrscheinlich deswegen so durch die Decke gegangen, weil er eine hinreichende Prise Verschwörungstheorie enthielt und eine vermeintlich so einfache Antwort für das lieferte, was viele sich ansonsten schlichtweg nicht vorstellen können. Oder wollen.
Ein Beitrag, der sachlich darauf eingegangen wäre, was solche Algorithmen denn tatsächlich schon können und was nicht, wäre vermutlich weitgehend unbeachtet geblieben, der Sache aber sicherlich dienlicher gewesen…
Maschinen sind so smart! Und gleichzeitig so doof…
Nun denn, man kann an diesem Beispiel recht gut erkennen, wo das Thema im Moment steht:
Der immense Hype um künstliche Intelligenz, um Deep Learning, um Computer, die beim Go und Schach gegen Großmeister gewinnen, lenkt viel Aufmerksamkeit und damit Wagniskapital, Forschungsgeld und schlaue Köpfe in diese Richtung.
Die verglichen mit früher enorm gewachsenen Datenmengen (nicht nur weil wir alle uns in Sozialen Medien bewegen, man denke auch an Fitnesstracker, Geodaten, Internet of Things etc.), die diese verarbeitende rapide gestiegene Rechnerleistung, der Preisverfall bei Speicher, all dies führt dazu, dass man gefühlt mittlerweile kaum noch ein anderes Thema kennt.
Serien wie Westworld, die davon handeln, dass man in perfekt inszenierte Kunstwelten bestehend aus Artificial Intelligence eintauchen kann, erfreuen sich großer Beliebtheit und das weniger, weil man diese wie noch 1973 (als das Westworld-Original in die Kinos kam) als herrlich schaurige Fiktion genießen konnte, sondern weil man inzwischen vieles davon für absolut vorstellbar hält.

Image Credit: HBO
Denn die Maschinen sind unheimlich schlau geworden.
Oder besser: Es wird an so viel Stellen mit soviel Hochdruck daran gearbeitet, sie schlau und schlauer werden zu lassen, dass jeder gut beraten ist, sich hiermit ein wenig zu befassen.
Insbesondere Personaler!
Ja, ich weiß, viele Personaler sind deshalb Personaler geworden, weil sie gerade nicht mit Maschinen, sondern mit Menschen arbeiten wollten. Deshalb herrscht hier auch eine ganz besonders ausgeprägte Vogel-Strauß-Haltung in Bezug auf die technischen Entwicklungen. Aber natürlich wird der Bereich HR hiervon nicht ausgespart bleiben und HR hat genau zwei Möglichkeiten damit umzugehen:
a. Visier aufklappen, sich schlau machen, versuchen, die Dinge und Entwicklungen zu beeinflussen, wenn möglich auch im HR-Sinne zu lenken. Stefan Reiser nannte es kürzlich “Von was mit Menschen zu was mit Menschen UND Technik“
oder
b. den Kopf (weiter) in den Sand stecken, so tun als gäbe es das alles nicht oder weiter mantramäßig argumentieren, dass “Maschinen das eh nie (vergleichbar gut) können werden” und man sich deshalb auch nicht weiter damit beschäftigen muss.
Ich werde nicht müde für Variante a. zu werben.
Man muss als HR´ler ja kein KI-Experte werden, aber ein regelmäßiger Blick in die einschlägige Szene, die ihr Wissen ja sogar bereitwillig in den jeweiligen Blogs und in Vorträgen teilt, sollte doch wohl möglich sein.
Vielleicht findet nämlich demnächst Google passende Jobs mit Hilfe eines ontologischen Algorithmus. Vielleicht werden Stellenanzeigen mit Hilfe von IBMs Tone Analyzer geschrieben. Vielleicht werden Anschreiben von IBMs Watson-Software und ein bisschen “Magic Sauce” gelesen und ausgewertet.
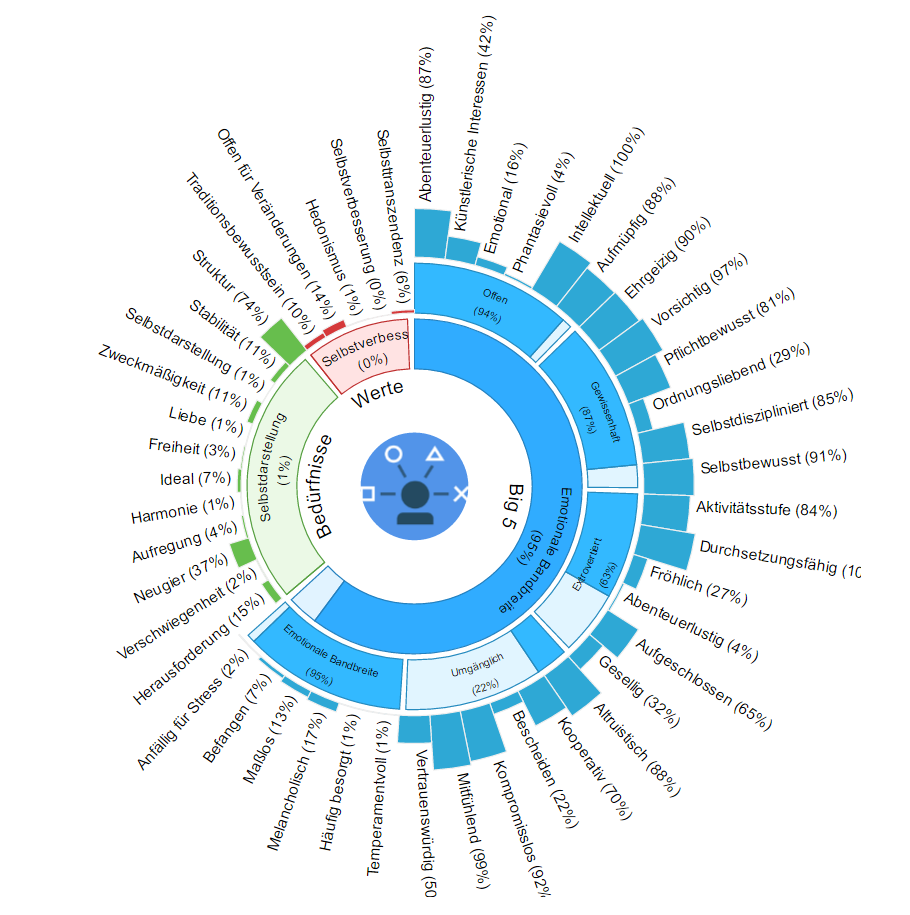
Vielleicht wird die Kündigungswahrscheinlichkeit eines Mitarbeiters vom Algorithmus beziffert.
Vielleicht errechnet ein Algorithmus die Persönlichkeitspassung einer Person zu einer Stelle (dazu demnächst mehr) oder den Cultural Fit eines Bewerbers mit einem Unternehmen (dazu auch). Vielleicht analysiert eine Maschine die Mimik eines Bewerbers und sagt wie dieser sich fühlt.

Vielleicht verrät die Stimme und deren Modulation wirklich etwas über die Persönlichkeit eines Bewerbers. Und vielleicht führen Roboter schneller die Auswahlinterviews als man denkt, als Chat mit Chatbot Mya oder von Angesicht zu Angesicht mit Matlda…
Tja, streicht das Wort “demnächst” und setzt die ganzen “vielleichts” in Klammern. Das alles gibt es nämlich schon.
Die Maschinen sind aber gleichzeitig auf eine gewisse Art nach wie vor dumm…
Man könnte also meinen, dass 2017 dann wohl an vielen Stellen den Durchbruch liefern wird, das Jahr von dem wir später einmal sagen werden, dass die Maschinen das Recruiting übernommen haben.
Nein, so wird es nicht kommen. Aber mit Betonung auf “so”, nicht auch “nicht”.
Erstens wird die Entwicklung sich evolutionär vollziehen, nicht mit einem großen Knall. Wenn wir ganz ehrlich sind, tut sie das ja schon seit Jahren.
Und zweitens wird es auch Sackgassen und Fehlschläge geben. Denn bei aller Euphorie um die technischen Möglichkeiten gibt es auch mindestens zwei gravierende Probleme:
Korrelation statt Kausalität
Die meisten Big Data Ansätze beruhen auf der Idee, die Rechenpower einzusetzen, um große und unstrukturierte Daten zu durchforsten. Das Ziel: Bislang unentdeckte Zusammenhänge entdecken.
Das ist super, wenn man dabei herausfindet, dass Bier und Windeln immer Samstagsvormittags besonders häufig gemeinsam gekauft werden, denn dann kann man sie, z.B. wenn man Wal-Mart heißt, im Laden gleich nebeneinander stellen. Aber was soll man aus dem mit .997 höchstkorrelierten Zusammenhang zwischen den US-Ausgaben für Wissenschaft, Raumfahrt und Technologie und der Zahl an Selbstmorden durch Erhängen, Strangulieren oder Ersticken für Schlüsse ziehen?
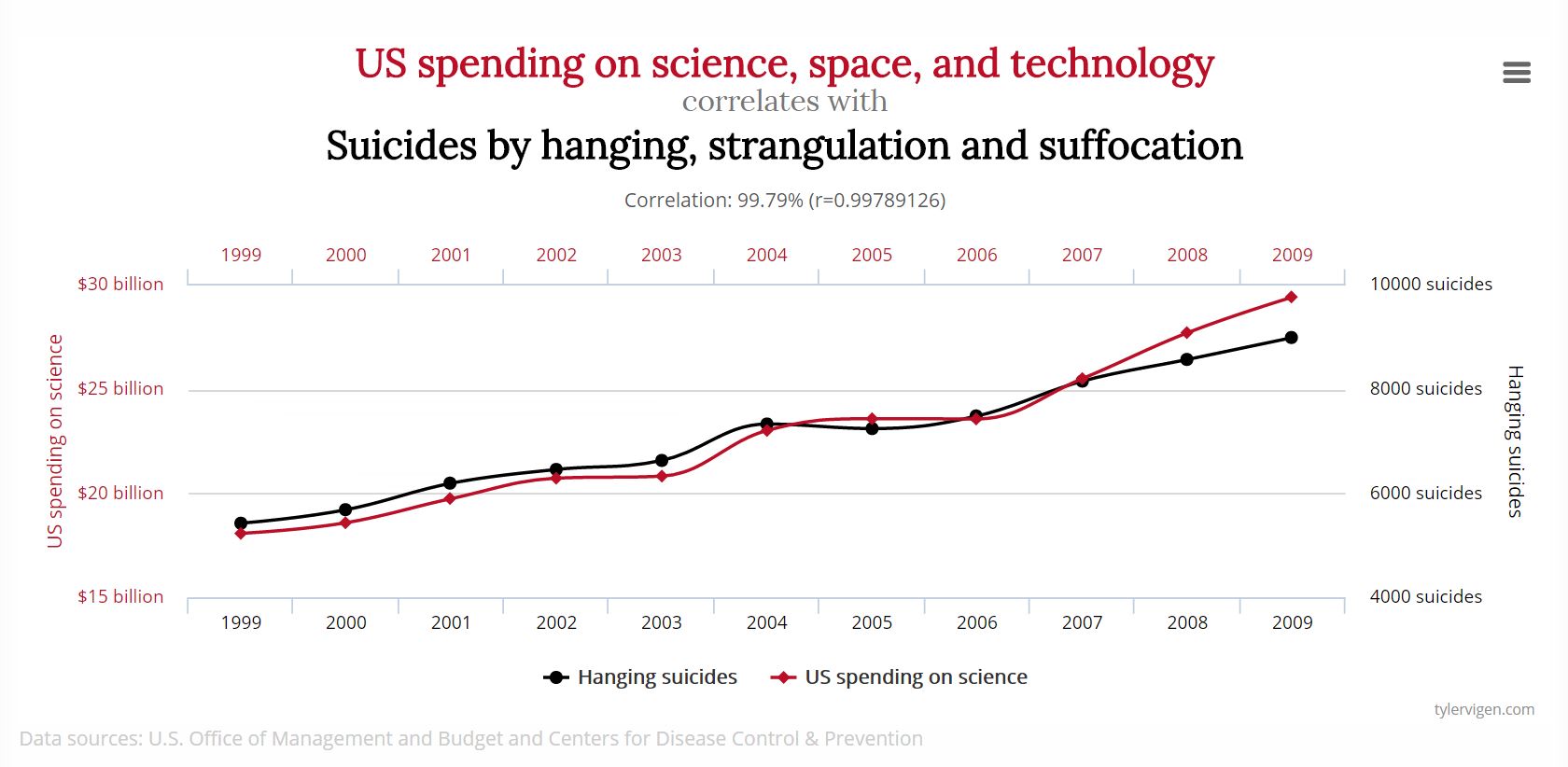
Genau. Natürlich keine! Hoffentlich.
Weil es sich um eine Scheinkorrelation handelt. Einen Zusammenhang ohne Grund.
Ein unkontrollierter Algorithmus aber würde natürlich die Ausgaben für Forschung kürzen in der hehren Absicht, die Selbstmordrate zu senken…
Von dieser Art gibt es unzählige Beispiele, eine Reihe besonders kurioser davon etwa findet sich auf der Website Spurious Correlations des Amerikaners Tyler Vigen.
Das Echokammer oder Filterblasen-Problem
Ein anderes, wenngleich technisch mit dem eben beschriebenen zusammenhängendes Problem ist das der sog. Echokammern oder Filterblasen. Wenn es ein Problem gibt, das uns spätestens der US-Wahlkampf vor Augen geführt hat, dann dieses.
Ich empfehle in diesem Zusammenhang jedem dringend, sich einmal 9 ruhige Minuten zu nehmen und sich den TED Talk des Internetaktivisten Eli Pariser aus 2011 zu Gemüte zu führen, auf den der Begriff der sog. Filter-Bubble zurückgeht.
Etwas kürzer wird es bei der Tagesschau erklärt.
Wem das auch noch zu lange dauert:
Das Filter-Bubble Problem ist folgendes: Der unendlich große Strom an Informationen wird von Algorithmen bewertet, nach (vermeintlicher) persönlicher Relevanz sortiert und dem Nutzer dann entsprechend dieser vermeintlichen persönlichen Relevanz präsentiert.
Das ist bei Facebook so, wo all das was die eigenen “Freunde” an Einträgen und Inhalten produzieren, teilen, kommentieren etc. vom Algorithmus für mich vorsortiert wird. Die Reihenfolge ist nicht chronologisch; vieles bekomme ich auch gar nicht mehr zusehen. Das ist bei Twitter so. Das ist auch bei Google so, wo die Trefferliste etwa der Suche nach der Begriffskombination “tolle Jobs in Hamburg” bei mir völlig anders ausfallen kann als bei meiner Frau. Warum? Weil wir möglicherweise darunter, was ein “toller Job in Hamburg” ist, durchaus verschiedener Ansicht sein können, vor allem aber, weil einem der Suchalgorithmus bei Google auch genau diesen Gefallen tun will: “Tolle Jobs in Hamburg” anzeigen.
Was die Kriterien sind, nach denen die Algorithmen diese Bewertung vornehmen, ist eine große Blackbox. Aber eines ist offenkundig: Die Algorithmen sind lernend.
Wenn ein Suchtreffer, den Googles Algorithmus auswirft, häufig geklickt wird, der Nutzer sich dann lange dort aufhält und möglicherweise sogar “weiterkonvertiert” (z.B. etwas kauft oder – um beim Beispiel zu bleiben – sich auf einen Job bewirbt), dann lernt der Algorithmus, dass sein Vorschlag wohl ein ganz guter war. Beim nächsten Mal steigt die Wahrscheinlichkeit, dass diesem Nutzer oder anderen Nutzern, die Google diesem Nutzer für ähnlich hält, wieder dieser Suchtreffer angezeigt wird.
Bei Facebook ist es so, dass das individuelle Like-Verhalten in den Algorithmus einfließt, der darüber entscheidet, was man in seine Timeline gespielt bekommt. Und wenn man kein “Gefällt mir-Kunde” der AfD-Facebookseite ist und auch der eigene Facebook-Freundeskreis nicht zu den “besorgten Bürgern” zählt, dann wird man diese Inhalte auch wahrscheinlich nicht zu sehen bekommen. Wenn doch, wird man sie wahrscheinlich nicht liken, was dann wiederum dem Algorithmus (der ja lernt) zu verstehen gibt, dass man eben solche nicht Inhalte für nicht so toll hält. Daraufhin wird er sie mir mit noch geringerer Wahrscheinlichkeit zeigen usw.
Irgendwann sehe ich also nur noch Inhalte, die mir “genehm” sind, ich nehme nur noch meine eigene Filterblase war. Alle sprechen gegen die eigene Wand und vernehmen nur noch das eigene Echo…
Dann fällt man nicht nur aus allen Wolken, wenn auf einmal jemand die Wahl gewinnt, den doch vorher “alle” für vollkommen unwählbar gehalten haben, sondern es fällt auch der für demokratische Prozesse so wichtige Diskurs mit anderen Meinungen aus. Da wo diese dann ggf. doch mal aufeinandertreffen, eskaliert es dann gleich (Hatespeech inklusive).
Microsofts Chat-Bot Tay wurde binnen kürzester Zeit durch den Dialog mit Twitter-Nutzern zum Holocaust leugnenden Rassisten – und das binnen weniger Stunden! -, eben weil das Regulativ fehlte…
Auf das Job-Matching übertragen könnte das bedeuten, dass mir der Algorithmus nur noch die Jobs vorschlägt, auf die ich auch selber gekommen wäre. Theoretisch zu ende gedacht: Er schlägt mir meinen eigenen aktuellen Job vor, denn der ist mir selbst ja am nächsten…
Die großen Internetmultis betonen zwar, sie seien selber kein Inhalteproduzent, sondern lediglich die Plattformen, auf denen diese Inhalte zu finden sein (“Wir waren´s nicht, die Maschine war´s!”), aber sie greifen über das Kuratieren und Filtern massiv in eben in diese Inhalte ein.
Algorithmen sind unheimlich gut. Aber ohne Kontrolle sind sie auch unheimlich gut darin, in eine falsche Richtung zu marschieren…
Kommen wir zum (Zwischen-)fazit:
Ich glaube, es ist für Personaler unerlässlich, sich nun endlich mit den Chancen und Risiken zu befassen, die mit der technischen Entwicklung hin zu einem möglichen Robot Recruiting einhergehen.
Nur dann wird HR erstens in der Lage sein, zu verstehen, was davon gut ist und was nicht und vor allem zweitens Einfluss auf die Entwicklung zu nehmen. Wie oben beschrieben kann ein alleingelassener Algorithmus – und damit meine ich auch: ein allein in den Händen der Techies liegender Algorithmus – nicht nur Unsinn produzieren, sondern auch gefährlich werden.
Hier geht es zwar nicht um die Frage, wer den Finger an den Knopf der Atombomben bekommt, aber falsche Mitarbeiter einzustellen, die richtigen abzulehnen oder nicht zu erkennen oder gleich gar nicht erst zu erreichen, ist eben auch nicht toll…
Ich glaube 2017 wird einen riesigen Schritt in Richtung “Robot Recruiting” bringen. Ob es dann fünf oder zehn Jahre dauert bis die Maschine die Führung übernimmt? We’ll see. Ich hoffe nur, dass auch HR das mitbekommt…
Ihr könnt ja diesen Kanal eingeschaltet lassen meinen Newsletter abonnieren, dann werdet Ihr es erfahren.
Auf ein tolles und hoffentlich in vielerlei Hinsicht weniger aufregendes 2017!
Sehr schöner, differenzierter Beitrag. Ich freue mich sehr auf die Entwicklungen in 2017, besonders im HR Bereich. Aber die Recruiter müssen es endlich schaffen ein allgemeines Interesse zu entwickeln und sich mit den Themen zu beschäftigen, die ihre Branche in Zukunft und schon in diesem Jahr bewegen werden.
Toller Beitrag, vielen Dank. Ich freue mich auf die Entwicklungen in 2017.
Zustimmen kann ich vor allem, dass sich Personaler nun hoffentlich mit den technologischen Möglichkeiten beschäftigen werden und die Angst ablegen müssen. Denn wie Sie richtig schreiben: Personaler wollen sich mit Menschen beschäftigen. Die Realität sieht nur leider so aus, dass Recruiter die meiste Zeit damit verbringen, sich mit Papier zu beschäftigen: Lebensläufe, Zeugnisse, ausgefüllte Formulare usw. Vielleicht versteht es ja der eine oder andere Recruiter, dass die KI genau das übernehmen kann – das Papier auswerten. Und der Recruiter hat wieder Zeit für den Menschen.
Freuen wir uns auf ein spannendes 2017!
Wie muss sich ein Arbeitnehmer fühlen, der ‘robotisiert’ eingestellt bzw. gefiltert wurde? Die Robotisierung kann schon einiges leisten http://www.dasgelbeforum.net/forum_entry.php?id=423989 und das in sehr vielen Arbeitsgebieten. Aber: Roboter sind doch bloss die ‘besseren Autisten’. Den Autisten fehlen die sog. Spiegelneuronen (bzw. diese sind unterrepräsentiert), weshalb sie Probleme haben, sich in andere hineinzuversetzen und z.B. Empathie zu empfinden. Genau die Fähigkeiten, die bisher im Einstellungsgespräch und der Personalauswahl entscheidend für die spätere Einpassung des ‘Neuen’ in seine/ihre Arbeitsumgebung waren!
Absolut richtig! Nur, dass große Teile der Personalauswahl heute eben keinerlei Spiegelneuronen verlangen. Da wo diese wichtig sind (Positivselektion) sehe ich auch perspektivisch vor allem Menschen. Das Problem ist nur leider: Je mehr Prozesse, die Maschinen eigentlich besser könnten, von Menschen gemacht werden müssen, desto weniger Zeit haben diese Menschen, die Dinge zu tun, die Menschen bessre können…